Claude 3.7 Sonnet 和 Claude Code
今天,我们发布 Claude 3.7 Sonnet¹,这是我们迄今为止最智能的模型,也是市场上首个混合推理模型。Claude 3.7 Sonnet 能够产生近乎即时的响应,或者进行扩展的、逐步的思考,这种思考过程对用户是可见的。API 用户还可以精细地控制模型可以思考 多久。
Claude 3.7 Sonnet 在编码和前端 Web 开发方面表现出尤为显著的改进。与该模型一同发布的,还有用于 Agentic Coding 的命令行工具 Claude Code。Claude Code 以有限的研究预览版形式提供,使开发者能够直接从终端将大量的工程任务委托给 Claude。
Claude 3.7 Sonnet 现已在所有 Claude 计划(包括 Free、Pro、Team 和 Enterprise)以及 Anthropic API、Amazon Bedrock 和 Google Cloud Vertex AI 上提供。扩展思考模式在除免费 Claude 层级之外的所有界面上均可用。
在标准和扩展思考模式下,Claude 3.7 Sonnet 的价格与其前代产品相同:每百万输入 token 3 美元,每百万输出 token 15 美元——包括思考 token。
Claude 3.7 Sonnet:将前沿推理变为现实
我们开发 Claude 3.7 Sonnet 的理念与其他市场上的推理模型有所不同。正如人类使用同一个大脑进行快速反应和深入思考一样,我们认为推理应该是前沿模型的集成能力,而不是完全独立的模型。这种统一的方法也为用户创造了更无缝的体验。
Claude 3.7 Sonnet 以多种方式体现了这种理念。首先,Claude 3.7 Sonnet 既是一个普通的 LLM,也是一个推理模型:您可以选择何时让模型正常回答,以及何时希望它在回答前进行更长时间的思考。在标准模式下,Claude 3.7 Sonnet 代表了 Claude 3.5 Sonnet 的升级版本。在扩展思考模式下,它会在回答前进行自我反思,从而提高其在数学、物理、指令跟随、编码和许多其他任务上的性能。我们通常发现,在这两种模式下,提示模型的工作方式类似。
其次,当通过 API 使用 Claude 3.7 Sonnet 时,用户还可以控制思考的 预算:您可以告诉 Claude 思考不超过 N 个 token,N 的值可以是从 0 到其 128K token 的输出限制之间的任何值。这使您可以在速度(和成本)与答案质量之间进行权衡。
第三,在开发我们的推理模型时,我们对数学和计算机科学竞赛问题的优化有所减少,而是将重点转向更好地反映企业实际如何使用 LLM 的现实世界任务。
早期测试 表明,Claude 在各个方面的编码能力都处于领先地位:Cursor 指出,Claude 再次成为现实世界编码任务的最佳选择,在从处理复杂代码库到高级工具使用等领域都有显著改进。Cognition 发现,在规划代码变更和处理全栈更新方面,它远胜于任何其他模型。Vercel 强调了 Claude 在复杂 Agent 工作流程中的卓越精度,而 Replit 已成功部署 Claude 从零开始构建复杂的 Web 应用程序和仪表板,而其他模型则停滞不前。在 Canva 的评估中,Claude 始终如一地生成可用于生产的代码,具有卓越的设计品味并大幅减少了错误。
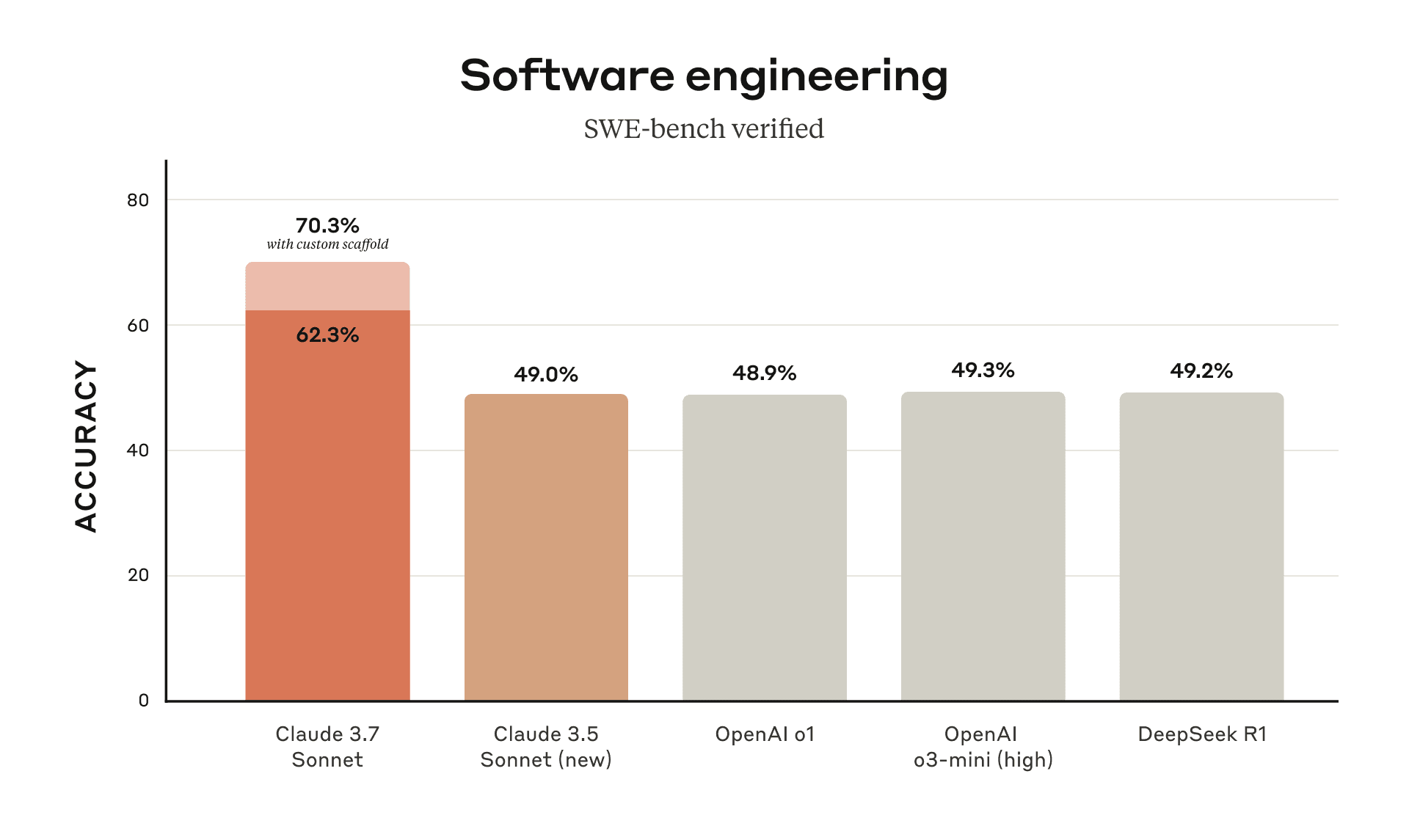
Claude 3.7 Sonnet 在 SWE-bench Verified 上取得了最先进的性能,该基准评估 AI 模型解决现实世界软件问题的能力。
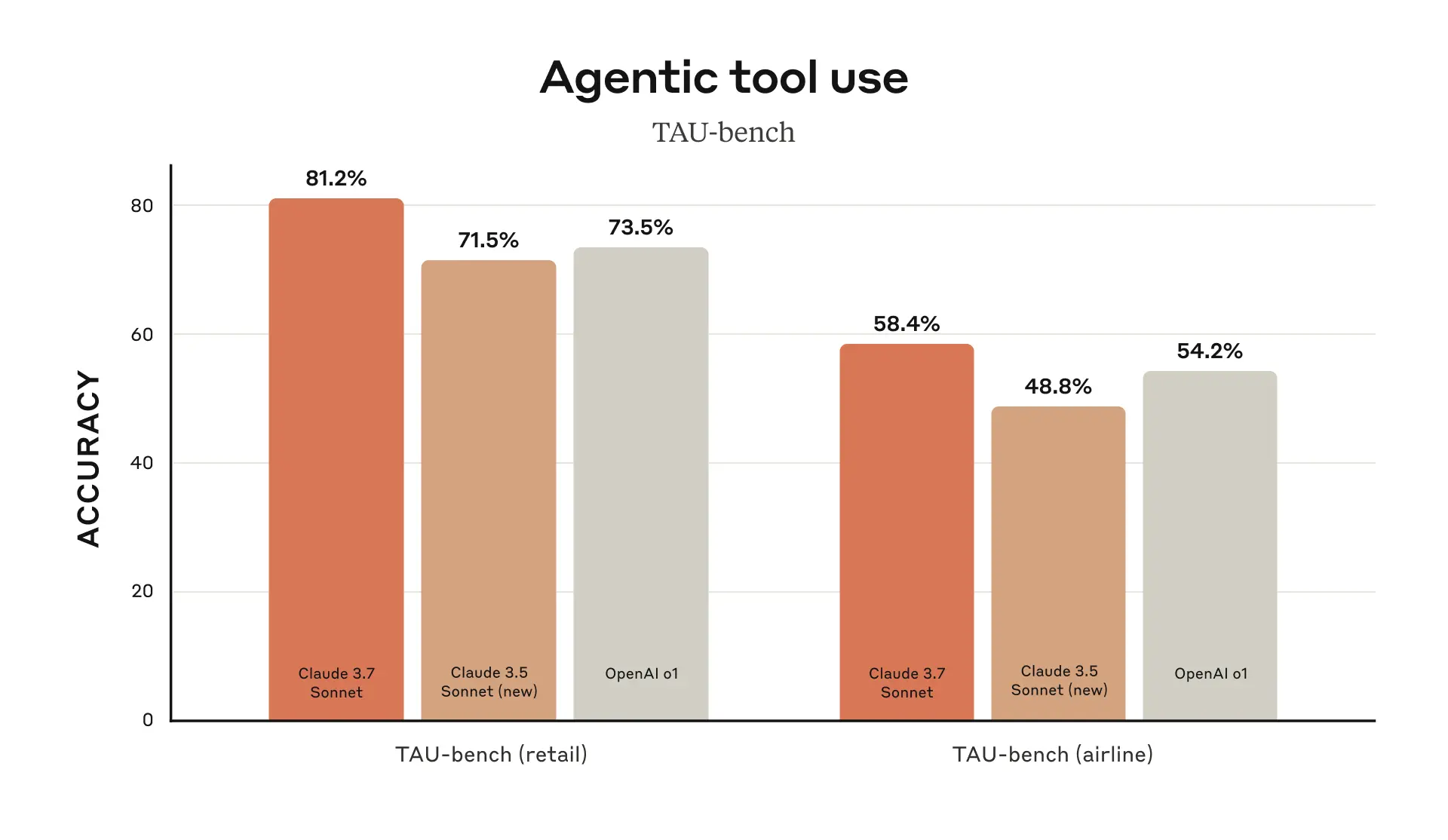
Claude 3.7 Sonnet 在 TAU-bench 上取得了最先进的性能,TAU-bench 是一个框架,用于测试 AI Agent 在涉及用户和工具交互的复杂现实世界任务中的表现。
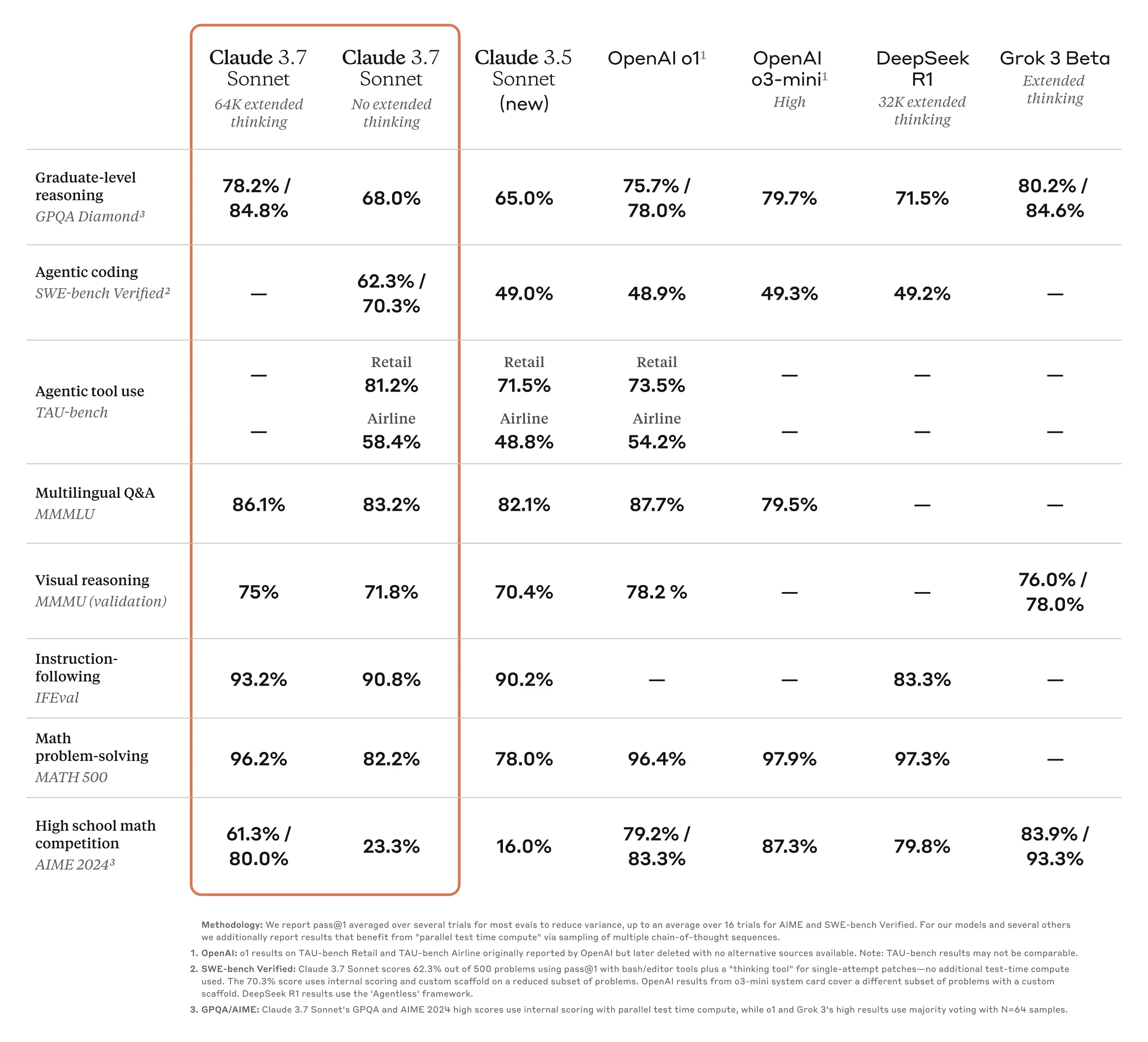
Claude 3.7 Sonnet 在指令跟随、通用推理、多模态能力和 Agentic Coding 方面表现出色,扩展思考模式在数学和科学方面提供了显著提升。除了传统的基准测试之外,它甚至在我们Pokémon 游戏性测试中也超越了所有先前的模型。
Claude Code
自 2024 年 6 月以来,Sonnet 已成为全球开发者首选的模型。今天,我们通过推出 Claude Code(我们的首个 Agentic Coding 工具)的有限研究预览版,进一步赋能开发者。
Claude Code 是一位积极的协作者,它可以搜索和阅读代码、编辑文件、编写和运行测试、提交代码并推送到 GitHub,以及使用命令行工具——在每一步都让您参与其中。
Claude Code 是一款早期产品,但已成为我们团队不可或缺的工具,尤其是在测试驱动开发、调试复杂问题和大规模重构方面。在早期测试中,Claude Code 在单次操作中完成了通常需要 45 分钟以上手动完成的任务,从而减少了开发时间和开销。
在接下来的几周内,我们计划根据我们的使用情况不断改进它:增强工具调用可靠性,增加对长时间运行命令的支持,改进应用内渲染,并扩展 Claude 对自身能力的理解。
我们推出 Claude Code 的目标是更好地了解开发者如何使用 Claude 进行编码,从而为未来的模型改进提供信息。通过加入此预览,您将获得与我们用于构建和改进 Claude 相同的强大工具,您的反馈将直接塑造其未来。
在您的代码库上与 Claude 合作
我们还改进了 Claude.ai 上的编码体验。我们的 GitHub 集成现已在所有 Claude 计划中提供——使开发者能够将其代码仓库直接连接到 Claude。
Claude 3.7 Sonnet 是我们迄今为止最好的编码模型。通过更深入地理解您的个人、工作和开源项目,它将成为更强大的合作伙伴,帮助您修复错误、开发功能以及构建最重要的 GitHub 项目的文档。
负责任地构建
我们对 Claude 3.7 Sonnet 进行了广泛的测试和评估,并与外部专家合作,以确保其符合我们的安全、保障和可靠性标准。与前代产品相比,Claude 3.7 Sonnet 也能更细致地区分有害和良性请求,不必要的拒绝减少了 45%。
此版本的系统卡涵盖了多个类别的新安全结果,详细分析了我们的“负责任的扩展策略”评估,其他 AI 实验室和研究人员可以将其应用于他们的工作。该卡还解决了计算机使用中出现的新风险,特别是 prompt injection attacks,并解释了我们如何评估这些漏洞并训练 Claude 来抵抗和缓解它们。此外,它还考察了推理模型可能带来的安全益处:理解模型如何做出决策的能力,以及模型推理是否真正值得信赖和可靠。阅读完整的系统卡以了解更多信息。
展望未来
Claude 3.7 Sonnet 和 Claude Code 标志着 AI 系统朝着真正增强人类能力的方向迈出了重要一步。凭借其深入推理、自主工作和有效协作的能力,它们使我们更接近 AI 丰富和扩展人类成就的未来。

我们很高兴您能探索这些新功能,并期待看到您将用它们创造什么。与往常一样,我们欢迎您提供反馈,以便我们继续改进和发展我们的模型。