DeepSeek-R1: How Reinforcement Learning Unleashes Reasoning in Large Language Models
Large Language Models (LLMs) have shown incredible progress, inching closer to the capabilities of Artificial General Intelligence (AGI). One of the most exciting advancements is in the realm of reasoning, where models are learning to solve complex problems that require multi-step logic and deduction.
In this blog post, we'll dive into a groundbreaking research paper from DeepSeek-AI: DeepSeek-R1, which explores how reinforcement learning (RL) can be used to significantly enhance the reasoning abilities of LLMs. Specifically, we will focus on these key aspects of the paper:
- DeepSeek-R1-Zero: A model trained purely with RL that demonstrates surprising reasoning skills.
- DeepSeek-R1: An improved model using a "cold start" with supervised data, showing performance comparable to OpenAI's models.
- Distillation: How these reasoning powers can be transferred to smaller, more efficient models.
- Unsuccessful Attempts: Some challenges during the research.
The Quest for Reasoning: Beyond Supervised Learning
Traditional LLMs are often trained using supervised fine-tuning (SFT), where the model learns from a massive dataset of input-output pairs. While effective, SFT has limitations when it comes to complex reasoning tasks. This is because reasoning often requires exploring a vast solution space, and it's impractical to create a supervised dataset that covers every possible scenario.
This is where reinforcement learning comes in. In RL, the model learns through trial and error by interacting with an environment and receiving rewards for desired behaviors. This allows the model to discover novel solutions and strategies that may not be present in any supervised dataset.
DeepSeek-R1-Zero: Reasoning from Scratch with Pure RL
The DeepSeek-AI team's first major contribution is DeepSeek-R1-Zero. This model is unique because it's trained purely through reinforcement learning, without any initial supervised fine-tuning. They used DeepSeek-V3-Base as the base model and employed the Group Relative Policy Optimization (GRPO) algorithm, which is introduced in the paper DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. The results are remarkable:
- Emergent Reasoning Behaviors: DeepSeek-R1-Zero naturally developed the ability to perform complex reasoning, including self-verification, reflection, and generating long chains of thought.
- Impressive Performance: On the AIME 2024 benchmark, DeepSeek-R1-Zero achieved a pass@1 score of 71.0%, and with majority voting, it reached 86.7%, matching the performance of OpenAI-o1-0912.
- Aha Moment: The model exhibited an "aha moment" where it learned to allocate more "thinking time" to a problem by reevaluating its initial approach, demonstrating a form of meta-cognition.
Here is the performance trajectory of DeepSeek-R1-Zero on the AIME 2024 benchmark:
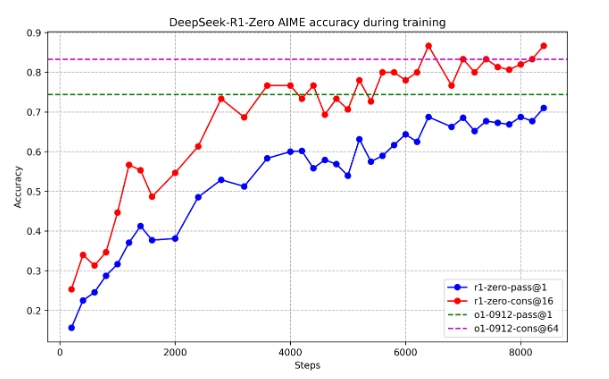
Figure AIME accuracy of DeepSeek-R1-Zero during training.
And here's a table summarizing the performance of DeepSeek-R1-Zero compared to OpenAI models:
| Model | AIME 2024 (pass@1) | AIME 2024 (cons@64) | MATH-500 (pass@1) | GPQA Diamond (pass@1) | LiveCode Bench (pass@1) | CodeForces (rating) |
|---|---|---|---|---|---|---|
| OpenAI-o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| OpenAI-o1-0912 | 74.4 | 83.3 | 94.8 | 77.3 | 63.4 | 1843 |
| DeepSeek-R1-Zero | 71.0 | 86.7 | 95.9 | 73.3 | 50.0 | 1444 |
Table Comparison of DeepSeek-R1-Zero and OpenAI o1 models on reasoning-related benchmarks.
How Does DeepSeek-R1-Zero Learn?
The key to DeepSeek-R1-Zero's success lies in its training process:
Training Template: The model is given a simple template to structure its responses, as shown below:
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User: prompt. Assistant:Template for DeepSeek-R1-Zero.
Reward System: A rule-based reward system provides feedback:
- Accuracy Rewards: Checks if the final answer is correct (e.g., using a compiler for coding problems).
- Format Rewards: Ensures the model puts its reasoning process between specific tags.
Limitations of DeepSeek-R1-Zero
Despite its strengths, DeepSeek-R1-Zero faced some challenges:
- Poor Readability: The model's output was often difficult to read, with formatting issues and mixed languages.
- Language Mixing: The model sometimes combined multiple languages in its responses.
DeepSeek-R1: Refining Reasoning with a Cold Start
To address these issues and push performance even further, the team developed DeepSeek-R1. This model incorporates a "cold start" phase where it's first fine-tuned on a small amount of high-quality, human-friendly supervised data. The training pipeline for DeepSeek-R1 consists of four stages:
Stage 1: Cold Start
Thousands of long Chain-of-Thought (CoT) examples are collected to fine-tune the DeepSeek-V3-Base model. The data is designed to be readable and follows the format:
| special_token | <reasoning_process> | special_token | <summary>
Stage 2: Reasoning-Oriented Reinforcement Learning
The fine-tuned model undergoes the same large-scale RL process as DeepSeek-R1-Zero, focusing on reasoning-intensive tasks. A language consistency reward is introduced to mitigate the issue of language mixing.
Stage 3: Rejection Sampling and Supervised Fine-Tuning
Once the RL process converges, the resulting checkpoint is used to generate more SFT data through rejection sampling. This stage also incorporates data from other domains (writing, role-playing, etc.) to enhance the model's general capabilities.
Stage 4: Reinforcement Learning for All Scenarios
A final RL stage is applied to improve helpfulness and harmlessness while further refining reasoning abilities. This stage uses a combination of rule-based rewards and reward models to guide the learning process.
DeepSeek-R1 Performance
DeepSeek-R1 achieves performance on par with OpenAI-o1-1217 on various benchmarks, as illustrated in the following figure:
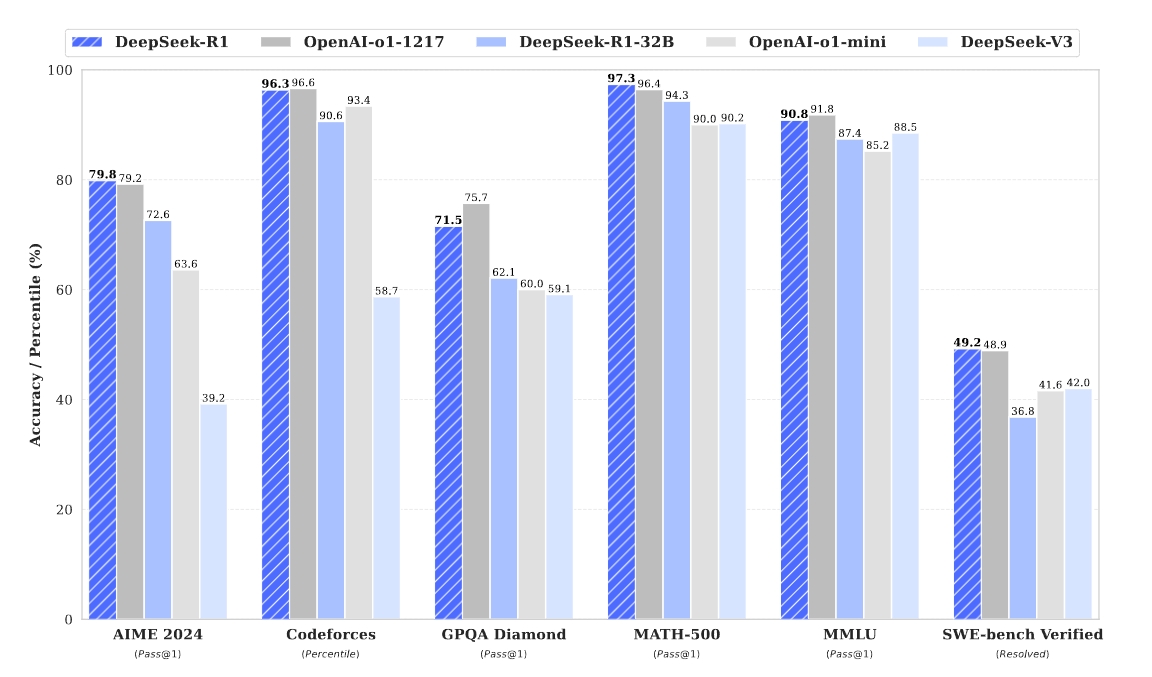
Figure Benchmark performance of DeepSeek-R1.
Here's a detailed comparison of DeepSeek-R1 with other state-of-the-art models:
| Benchmark | Metric | Claude-3.5-Sonnet-1022 | GPT-40-0513 | DeepSeek-V3 | OpenAI-o1-mini | OpenAI-o1-1217 | DeepSeek-R1 |
|---|---|---|---|---|---|---|---|
| MMLU | Pass@1 | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 |
| AIME 2024 | Pass@1 | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500 | Pass@1 | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 |
| Codeforces (Percentile) | Percentile | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 |
| LiveCodeBench | Pass@1-COT | 38.9 | 32.9 | 36.2 | 53.8 | 63.4 | 65.9 |
| GPQA Diamond | Pass@1 | 65.0 | 49.9 | 59.1 | 60.0 | 75.7 | 71.5 |
| AlpacaEval2.0 | LC-winrate | 52.0 | 51.1 | 70.0 | 57.8 | - | 87.6 |
| ArenaHard | GPT-4-1106 | 85.2 | 80.4 | 85.5 | 92.0 | - | 92.3 |
Table Comparison between DeepSeek-R1 and other representative models.
Distillation: Sharing the Reasoning Gift
One of the most exciting aspects of this research is the demonstration that the reasoning capabilities learned by DeepSeek-R1 can be distilled into smaller, more efficient models. The team fine-tuned several smaller models, including Qwen and Llama, using the data generated by DeepSeek-R1.
Here are some key results:
- DeepSeek-R1-Distill-Qwen-7B outperforms larger non-reasoning models like GPT-40-0513.
- DeepSeek-R1-Distill-Qwen-14B surpasses the strong open-source model QwQ-32B-Preview on all evaluation metrics.
- DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Llama-70B significantly exceed OpenAI-o1-mini on most benchmarks.
| Model | AIME 2024 (pass@1) | MATH-500 (pass@1) | GPQA Diamond (pass@1) | LiveCode Bench (pass@1) | CodeForces (rating) |
|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 94.5 | 65.2 | 57.5 | 1633 |
Table Comparison of DeepSeek-R1 distilled models and other comparable models on reasoning-related benchmarks.
Unsuccessful Attempts: Learning from Setbacks
The paper also honestly discusses some approaches that didn't work as expected:
- Process Reward Model (PRM): While theoretically sound, PRMs were challenging to implement effectively due to the difficulty in defining fine-grained steps and the risk of reward hacking.
- Monte Carlo Tree Search (MCTS): MCTS struggled to scale up due to the vast search space of token generation and the difficulty in training a reliable value model.
These "failures" are valuable because they provide insights into the challenges of developing reasoning models and highlight the need for further research.
Conclusion and Future Directions
The DeepSeek-R1 research represents a significant step forward in developing LLMs with strong reasoning capabilities. The use of reinforcement learning, both with and without a supervised cold start, has proven to be a powerful approach. Moreover, the ability to distill these reasoning skills into smaller models opens up exciting possibilities for deploying advanced reasoning in resource-constrained environments.
The authors also outline several promising directions for future work:
- Improving General Capabilities: Enhancing DeepSeek-R1's performance on tasks like function calling, multi-turn conversation, and complex role-playing.
- Addressing Language Mixing: Optimizing the model for languages beyond Chinese and English.
- Refining Prompting Engineering: Reducing the model's sensitivity to prompt variations.
- Tackling Software Engineering Tasks: Applying large-scale RL more effectively to software engineering benchmarks.
This research is a testament to the power of reinforcement learning in unlocking new levels of intelligence in artificial systems. As LLMs continue to evolve, we can expect even more impressive reasoning capabilities to emerge, bringing us closer to the goal of AGI.