DeepSeek-R1:如何利用强化学习释放大型语言模型的推理能力
近年来,大型语言模型 (LLM) 取得了令人瞩目的进步,逐渐逼近通用人工智能 (AGI) 的能力。其中最激动人心的进展之一是在推理领域,模型正在学习解决需要多步骤逻辑和演绎的复杂问题。
在本篇博客文章中,我们将深入探讨 DeepSeek-AI 的一项突破性研究:DeepSeek-R1 。该研究探索了如何利用强化学习 (RL) 来显著增强 LLM 的推理能力。具体来说,我们将重点关注论文的以下几个关键方面:
- DeepSeek-R1-Zero:一个完全使用 RL 训练的模型,展示了令人惊讶的推理能力。
- DeepSeek-R1:一个使用监督数据进行“冷启动”的改进模型,其性能可与 OpenAI 的模型相媲美。
- 知识蒸馏:如何将这些推理能力转移到更小、更高效的模型中。
- 不成功的尝试:在研究过程中遇到的一些挑战。
推理的探索:超越监督学习
传统的大型语言模型通常使用监督微调 (SFT) 进行训练,模型从大量的输入-输出对数据集中学习。虽然有效,但 SFT 在处理复杂的推理任务时存在局限性。这是因为推理通常需要在庞大的解决方案空间中进行探索,而创建一个覆盖所有可能场景的监督数据集是不切实际的。
这就是强化学习发挥作用的地方。在 RL 中,模型通过与环境交互并在理想行为上收到奖励,从而通过反复试错来进行学习。这使得模型能够发现任何监督数据集中可能不存在的新颖解决方案和策略。
DeepSeek-R1-Zero:使用纯 RL 从头开始推理
DeepSeek-AI 团队的第一个主要贡献是 DeepSeek-R1-Zero。这个模型非常独特,因为它完全通过强化学习进行训练,没有任何初始的监督微调。他们使用 DeepSeek-V3-Base 作为基础模型,并采用了论文 DeepSeekMath: 提升开放语言模型数学推理的极限 中介绍的组相对策略优化 (GRPO) 算法。结果令人瞩目:
- 涌现的推理行为:DeepSeek-R1-Zero 自然而然地发展出执行复杂推理的能力,包括自我验证、反思和生成长推理链。
- 令人印象深刻的性能:在 AIME 2024 基准测试中,DeepSeek-R1-Zero 实现了 71.0% 的 pass@1 分数,而在多数投票机制下,它的分数达到了 86.7%,与 OpenAI-o1-0912 的性能相当。
- “顿悟”时刻:该模型展现出了一个“顿悟”时刻,它通过重新评估其初始方法来学习为问题分配更多的“思考时间”,展示了一种元认知形式。
以下是 DeepSeek-R1-Zero 在 AIME 2024 基准测试中的性能轨迹:
![DeepSeek-R1-Zero AIME accuracy during training]vs
图 DeepSeek-R1-Zero 在训练过程中的 AIME 准确率。
下表总结了 DeepSeek-R1-Zero 与 OpenAI 模型相比的性能:
| 模型 | AIME 2024 (pass@1) | AIME 2024 (cons@64) | MATH-500 (pass@1) | GPQA Diamond (pass@1) | LiveCode Bench (pass@1) | CodeForces (rating) |
|---|---|---|---|---|---|---|
| OpenAI-o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| OpenAI-o1-0912 | 74.4 | 83.3 | 94.8 | 77.3 | 63.4 | 1843 |
| DeepSeek-R1-Zero | 71.0 | 86.7 | 95.9 | 73.3 | 50.0 | 1444 |
表 DeepSeek-R1-Zero 和 OpenAI o1 模型在推理相关基准上的比较。
DeepSeek-R1-Zero 是如何学习的?
DeepSeek-R1-Zero 成功的关键在于其训练过程:
训练模板:模型被赋予一个简单的模板来组织其响应,如下所示:
用户和助手之间的一段对话。用户提出问题,助手解决问题。助手首先在脑海中思考推理过程,然后向用户提供答案。推理过程和答案分别包含在 <think> </think> 和 <answer> </answer> 标签中,即 <think> reasoning process here </think> <answer> answer here </answer>。用户:prompt。助手:表 DeepSeek-R1-Zero 的模板。
奖励系统:基于规则的奖励系统提供反馈:
- 准确性奖励:检查最终答案是否正确(例如,对代码问题使用编译器)。
- 格式奖励:确保模型将其推理过程放在特定的标签之间。
DeepSeek-R1-Zero 的局限性
尽管 DeepSeek-R1-Zero 具有优势,但也面临着一些挑战:
- 可读性差:该模型的输出通常难以阅读,存在格式问题和混合语言。
- 语言混合:该模型有时会在其响应中混合多种语言。
DeepSeek-R1:通过冷启动改进推理
为了解决这些问题并进一步提高性能,该团队开发了 DeepSeek-R1。该模型加入了一个“冷启动”阶段,在这个阶段中,它首先在少量高质量、人性化的监督数据上进行微调。DeepSeek-R1 的训练流程包括四个阶段:
阶段 1:冷启动
收集数千个长思维链 (CoT) 示例来微调 DeepSeek-V3-Base 模型。这些数据被设计成可读的,并遵循以下格式:
| special_token | <reasoning_process> | special_token | <summary>
阶段 2:面向推理的强化学习
经过微调的模型会经历与 DeepSeek-R1-Zero 相同的大规模 RL 过程,重点是推理密集型任务。引入语言一致性奖励以减轻语言混合的问题。
阶段 3:拒绝采样和监督微调
一旦 RL 过程收敛,所产生的检查点将通过拒绝采样来生成更多 SFT 数据。这个阶段还加入了来自其他领域(写作、角色扮演等)的数据,以增强模型的通用能力。
阶段 4:适用于所有场景的强化学习
应用最后一个 RL 阶段来提高有用性和无害性,同时进一步改进推理能力。这个阶段使用基于规则的奖励和奖励模型相结合的方式来指导学习过程。
DeepSeek-R1 的性能
DeepSeek-R1 在各种基准测试中取得了与 OpenAI-o1-1217 相媲美的性能,如下图所示:
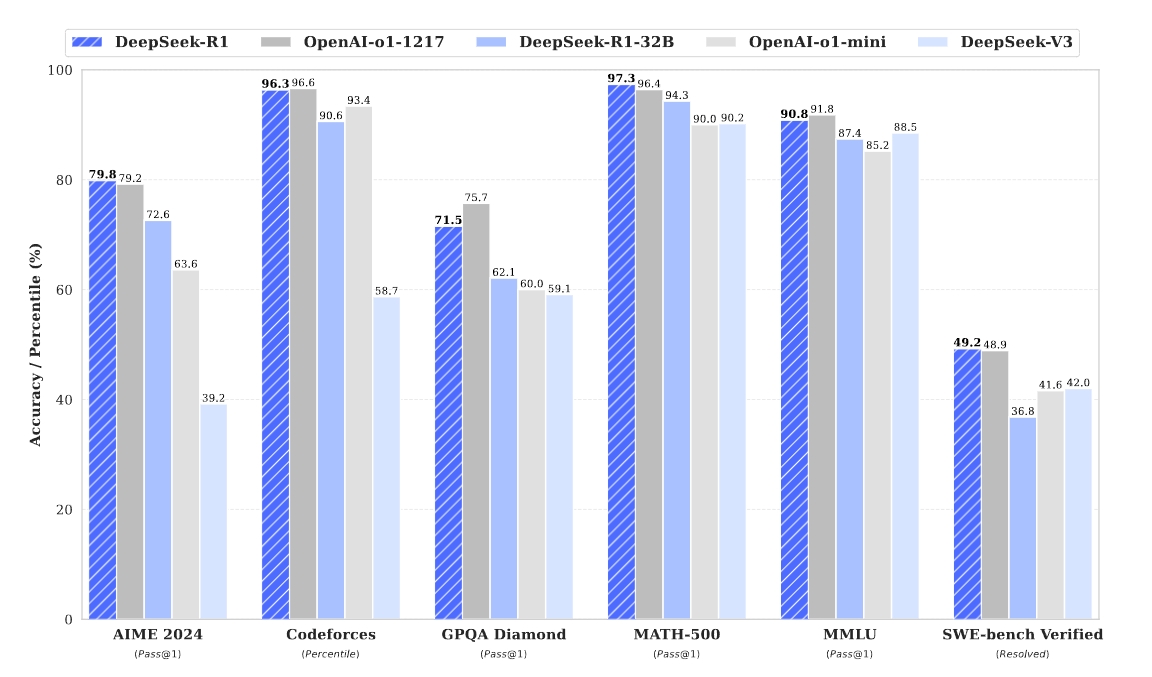
图 DeepSeek-R1 的基准性能。
下表详细比较了 DeepSeek-R1 与其他最先进的模型:
| 基准测试 | 指标 | Claude-3.5-Sonnet-1022 | GPT-40-0513 | DeepSeek-V3 | OpenAI-o1-mini | OpenAI-o1-1217 | DeepSeek-R1 |
|---|---|---|---|---|---|---|---|
| MMLU | Pass@1 | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 |
| AIME 2024 | Pass@1 | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500 | Pass@1 | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 |
| Codeforces (百分位) | 百分位 | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 |
| LiveCodeBench | Pass@1-COT | 38.9 | 32.9 | 36.2 | 53.8 | 63.4 | 65.9 |
| GPQA Diamond | Pass@1 | 65.0 | 49.9 | 59.1 | 60.0 | 75.7 | 71.5 |
| AlpacaEval2.0 | LC-winrate | 52.0 | 51.1 | 70.0 | 57.8 | - | 87.6 |
| ArenaHard | GPT-4-1106 | 85.2 | 80.4 | 85.5 | 92.0 | - | 92.3 |
表 DeepSeek-R1 与其他代表性模型的比较。
知识蒸馏:分享推理能力
这项研究最激动人心的方面之一是证明了 DeepSeek-R1 学习到的推理能力可以蒸馏到更小、更高效的模型中。该团队使用 DeepSeek-R1 生成的数据对几个较小的模型进行了微调,包括 Qwen 和 Llama。
以下是一些关键结果:
- DeepSeek-R1-Distill-Qwen-7B 的性能优于 GPT-40-0513 等较大的非推理模型。
- DeepSeek-R1-Distill-Qwen-14B 在所有评估指标上均优于强大的开源模型 QwQ-32B-Preview。
- DeepSeek-R1-Distill-Qwen-32B 和 DeepSeek-R1-Distill-Llama-70B 在大多数基准测试中均显著优于 OpenAI-o1-mini。
| 模型 | AIME 2024 (pass@1) | MATH-500 (pass@1) | GPQA Diamond (pass@1) | LiveCode Bench (pass@1) | CodeForces (rating) |
|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 94.5 | 65.2 | 57.5 | 1633 |
表 DeepSeek-R1 蒸馏模型与其他可比较模型在推理相关基准上的比较。
不成功的尝试:从挫折中学习
该论文还诚实地讨论了一些未达到预期效果的方法:
- 过程奖励模型 (PRM):虽然理论上合理,但由于难以定义细粒度的步骤以及存在奖励攻击的风险,PRM 难以有效地实施。
- 蒙特卡洛树搜索 (MCTS):由于令牌生成的庞大搜索空间以及难以训练可靠的价值模型,MCTS 难以扩展。
这些“失败”很有价值,因为它们提供了关于开发推理模型所面临挑战的见解,并强调了进一步研究的必要性。
总结和未来方向
DeepSeek-R1 研究代表了在开发具有强大推理能力的 LLM 方面向前迈出的重要一步。事实证明,无论有没有监督的冷启动,使用强化学习都是一种强大的方法。此外,将这些推理能力提炼成更小模型的能力为在资源受限的环境中部署高级推理开辟了令人兴奋的可能性。
作者还概述了未来工作的几个有希望的方向:
- 提高通用能力:增强 DeepSeek-R1 在函数调用、多轮对话和复杂角色扮演等任务上的性能。
- 解决语言混合问题:优化模型以支持中文和英文以外的语言。
- 改进提示工程:降低模型对提示变化的敏感性。
- 处理软件工程任务:将大规模 RL 更有效地应用于软件工程基准测试。
这项研究证明了强化学习在释放人工智能系统新智能水平方面的强大作用。随着 LLM 的不断发展,我们可以期待更令人印象深刻的推理能力出现,使我们更接近 AGI 的目标。