我是如何思考LLM提示工程的
2013 年,在谷歌,Mikolov 等人注意到一些非凡的现象。
他们正在构建一个模型,将词语嵌入到向量空间中——这个问题在当时已有悠久的学术历史,可追溯至 20 世纪 80 年代。他们的模型采用了一种优化目标,旨在将词语间的相关性关系转化为嵌入空间中的距离关系:词汇表中的每个词语都关联一个向量,并通过优化使得表示频繁共现词语的向量之间的点积(余弦相似度)更接近 1,而表示罕见共现词语的向量之间的点积则更接近 0。
他们发现,生成的嵌入空间不仅仅捕捉了语义相似性,还具备某种形式的涌现学习能力——它能够执行“词算术”,这是它未曾被训练过的任务。在空间中存在一个向量,可以加到任何男性名词上,得到一个接近其女性等价物的点。例如:V(king) - V(man) + V(woman) = V(queen)。这就是一个“性别向量”。相当酷!似乎还有数十个这样的神奇向量——一个复数向量,一个从野生动物名称到其最接近宠物名称的向量,等等。
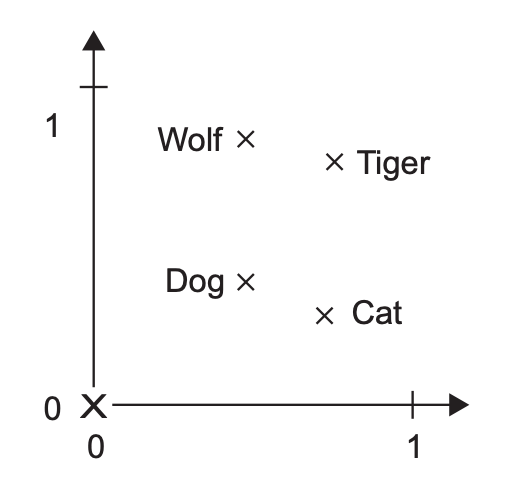
图示:一个 2D 嵌入空间,使得连接“狼”到“狗”的向量与连接“虎”到“猫”的向量相同。
Word2Vec 与 LLMs:海布学习类比
快进十年——我们现在进入了LLMs的时代。表面上,现代LLMs与原始的 word2vec 模型似乎相去甚远。它们能生成极其流畅的语言——这是 word2vec 完全无法做到的——并且似乎对任何话题都了如指掌。然而,它们实际上与老派的 word2vec 有很多共同之处。
两者都涉及将标记(单词或子词)嵌入向量空间。它们都依赖于相同的基本原理来学习这个空间:一起出现的标记在嵌入空间中最终会彼此靠近。用于比较标记的距离函数在这两种情况下是相同的:余弦距离。甚至嵌入空间的维度也相似:大约在 10e3 或 10e4 的量级。
你可能会问——等等,我听说LLMs是自回归模型,训练用于根据前面的词序列预测下一个词。这与 word2vec 的目标——最大化共现词之间的点积——有什么关系呢?
实际上,LLMs 确实似乎在相近位置编码了相关的标记,因此必然存在某种联系。答案就是自注意力机制。
自注意力机制是 Transformer 架构中最重要的组成部分。它是一种通过线性重组来自某个先前空间的词嵌入,以加权组合的方式学习新的词嵌入空间的机制,其中赋予那些已经“更接近”的词嵌入更大的重要性(即,具有更高点积的词嵌入)。它倾向于将已经接近的词向量拉得更近——随着时间的推移,导致词的相关关系转化为嵌入空间的接近关系(以余弦距离衡量)。Transformer 通过学习一系列基于前一个空间元素重组的渐进细化嵌入空间来工作。
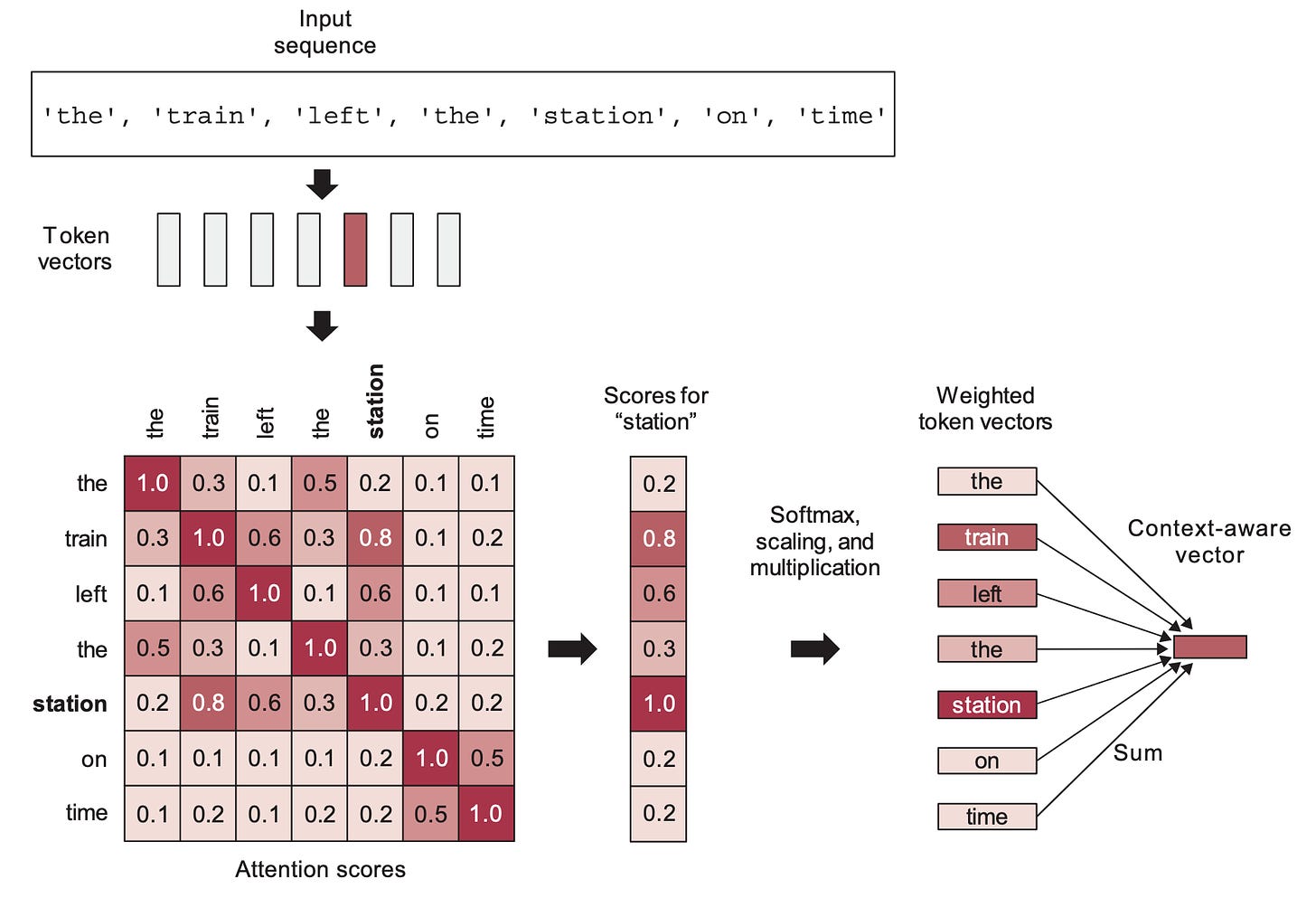
自注意力机制的工作原理:此处计算“station”与序列中每个其他单词之间的注意力得分,然后使用这些得分对词向量进行加权求和,生成的向量即为新的“station”向量。
自注意力机制赋予 Transformer 两个关键特性:
- 它们学习的嵌入空间在语义上是连续的,即在嵌入空间中稍作移动,只会使对应词元的面向人类的意义发生轻微变化。word2vec 空间也验证了这一特性。
- 它们学习的嵌入空间在语义上是可插值的,即在嵌入空间中取两个点之间的中间点会产生一个代表相应标记之间“中间含义”的点。这是因为每个新的嵌入空间都是通过在前一个空间中的向量之间进行插值构建的。
这与你所知的大脑学习方式并非完全不同。大脑中的关键学习原则是赫布学习——简而言之,“一起激发的神经元会连接在一起”。神经元激发事件(可能代表动作或感知输入)之间的相关性关系在大脑网络中转化为接近性关系,就像 Transformer(以及 word2vec)将相关性关系转化为向量接近性关系一样。两者都是信息空间的映射。
从新兴的单词算术到新兴的向量程序
当然,word2vec 与 LLMs 之间也存在显著差异。Word2vec 并非为生成文本采样而设计。LLMs 的规模要大得多,能够编码更为复杂的变换。事实上,word2vec 更像是一个玩具模型:它在语言建模中的地位,就如同在 MNIST 像素上进行逻辑回归之于最先进的图像计算机视觉模型。基本原理大致相同,但玩具模型缺乏任何有意义的表示能力。Word2vec 甚至不是一个深度神经网络——它采用浅层、单层架构。与此同时,LLMs 拥有迄今为止任何人训练过的模型中最高的表示能力——它们包含数十层 Transformer,总计数百层,参数数量达到数十亿级别。
与 word2vec 类似,LLMs 在将标记组织到向量空间的过程中,作为副产品学习到了有用的语义功能。但由于这种增强的表示能力和更为精细的自回归优化目标,我们不再局限于像“性别向量”或“复数向量”这样的线性变换。LLMs 可以存储任意复杂的向量函数——事实上,如此复杂,以至于更准确地说,它们应被称为向量程序而非函数。
Word2vec 使您能够完成一些基本操作,例如 plural(cat) → cats 或 male_to_female(king) → queen。与此同时,LLMs 可以实现纯粹的魔法——比如 write_this_in_style_of_shakespeare(“…你的诗…”) → “…新诗…”。而且它们包含了数百万个这样的程序。
LLMs 作为程序数据库
你可以将LLM视为一个数据库:它存储信息,你可以通过提示来检索这些信息。但LLMs与数据库之间有两个重要区别。
第一个区别在于,LLM 是一种连续、插值型的数据库。与存储为离散条目不同,您的数据被存储为向量空间——一条曲线。您可以在曲线上移动(正如我们讨论的,它在语义上是连续的),以探索附近的相关点。您还可以在曲线上的不同数据点之间进行插值,以找到它们之间的中间点。这意味着您可以从数据库中检索到比存入的更多的信息——尽管并非所有信息都准确或有意义。插值可能导致泛化,但也可能导致幻觉。
第二个区别是,LLM不仅仅包含数据。它确实包含大量数据——事实、地点、人物、日期、事物、关系。但它也是一个——或许主要是一个——程序数据库。
它们并不是你习惯处理的那种程序,请注意。你可能会想到确定性的 Python 程序——一系列符号语句逐步处理数据。但这并不是。相反,这些向量程序是高度非线性的函数,将潜在嵌入空间映射到自身。类似于 word2vec 的神奇向量,但复杂得多。
作为程序查询的提示
要从LLM中获取信息,你必须向它发出提示。如果一个LLM就像一个包含数百万个向量程序的数据库,那么提示就像是在该数据库中的搜索查询。你的提示部分可以被解释为“程序键”,即你想要检索的程序的索引,而另一部分则可以被解释为程序的输入。
考虑以下示例提示:“rewrite the following poem in the style of Shakespeare: …my poem…”

- “rewrite this in the style of” 是程序键。它指向程序空间中的特定位置。
- “Shakespeare”和“..my poem…”是程序输入。
- 程序执行结果是LLM的输出。
现在,请记住,LLM作为程序数据库的类比仅仅是一个思维模型——你还可以使用其他模型。一个更常见但不太直观的模型是,将LLMs视为自回归文本生成器,它们根据训练数据的分布输出最有可能跟随你提示的单词序列——即专注于LLMs被优化的任务。如果你能记住多种建模它们工作方式的方法,你将更好地理解LLMs——希望你会发现这个新模型有用。
提示工程作为程序搜索过程
请记住,这个“程序数据库”是连续且可插值的——它不是一个离散的程序集合。这意味着,即使提示稍有不同,例如“以 x 的风格重新改写这段文字的歌词”,仍然会指向程序空间中非常相似的位置,从而生成一个行为非常接近但并不完全相同的程序。
您可以使用成千上万种变体,每种变体都会产生一个相似但略有不同的程序。这就是为什么需要提示工程。没有先验的理由认为您最初的天真程序键会导致任务的最佳程序。LLM 不会“理解”您的意图并以最佳方式执行——它只是会从您提示指向的众多可能位置中获取程序。
提示工程是搜索程序空间以找到在目标任务上经验上表现最佳的程序的过程。这与在搜索软件时尝试不同的关键词并无不同。
如果LLMs 真的理解了你告诉他们的内容,那么这个搜索过程就没有必要了,因为关于你的目标任务所传达的信息量并不会因为你使用“重写”而不是“改写”,或者你在提示前加上“逐步思考”而改变。永远不要假设LLM 第一次就能“理解”——请记住,你的提示不过是无尽程序海洋中的一个地址,所有这些程序都是通过自回归优化目标将标记组织成向量空间的副产品。
一如既往,理解LLMs最重要的原则是,你应该抵制将其拟人化的诱惑。