LLM 量化对比
量化 (Quantization) 是高效部署大型语言模型 (LLM) 的关键技术,它可以减少内存占用并提高推理速度。然而,较低的精度通常会导致模型质量的权衡。在本文中,我们比较了各种量化程度,分析了它们对速度和输出质量的影响。
性能对比
下表展示了应用于 DeepSeek-R1-Abliterated 模型的不同量化级别的性能对比。这些模型在各种任务上进行了评估。LiveBench 评估了模型在 17 个任务中的性能,这些任务分为 6 个类别。 让我们逐个查看这些类别。
代码 (Coding)
代码生成和来自 Leetcode/AtCoder 的新型代码补全任务 (LiveCodeBench)。
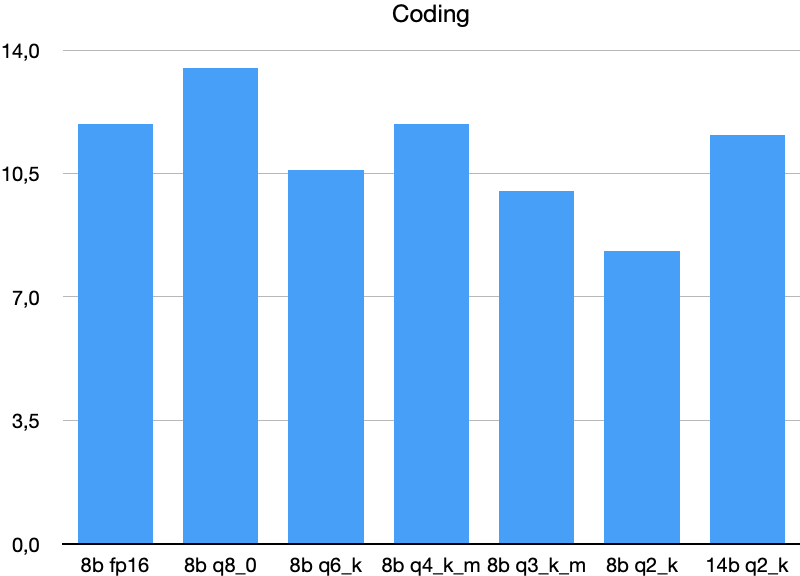
低比特量化 (Q3_K_M, Q2_K) 显著降低了分数。
数据分析 (Data Analysis)
使用最新的 Kaggle/Socrata 数据集的任务,包括表格重新格式化、列连接预测和类型注释。
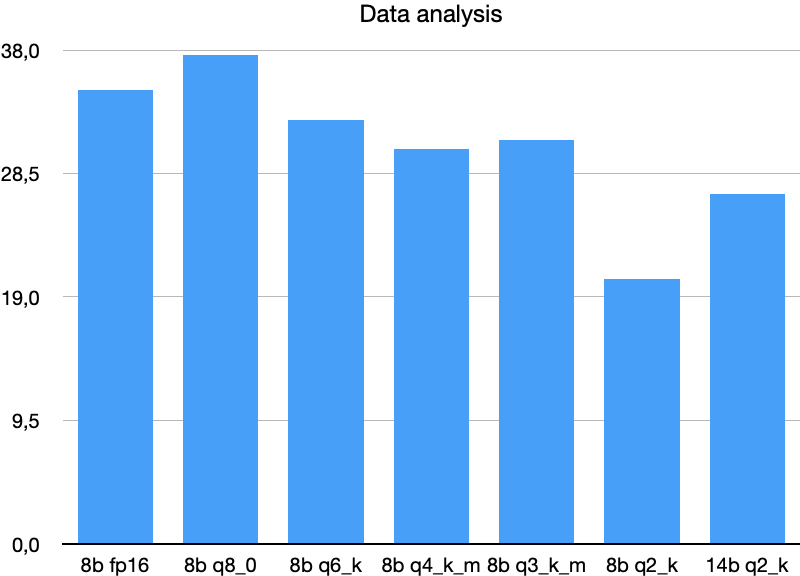
量化对数据分析任务的影响与代码任务类似。
指令跟随 (Instruction Following)
基于最近的新闻文章进行释义、总结和故事讲述,并遵循特定的约束。
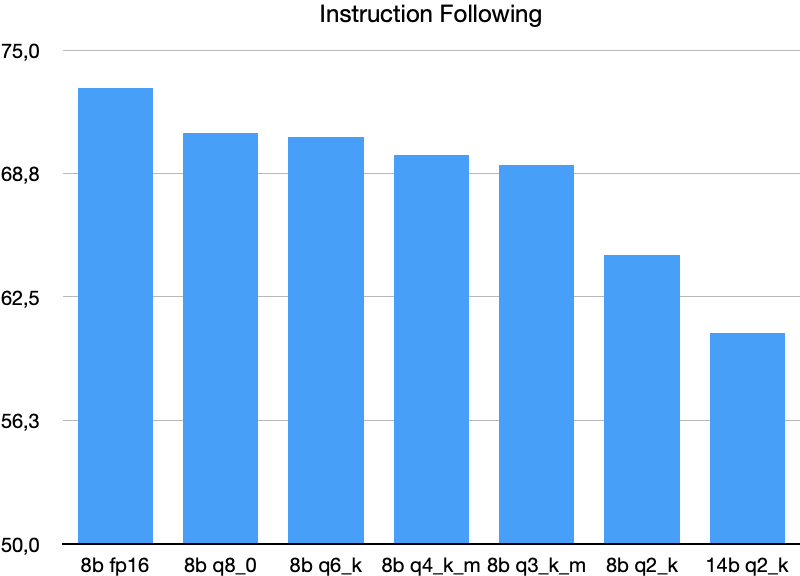
注意,图表的纵轴在 50 的值处被截断了!
量化略微降低了性能。与代码和数据分析不同,14B Q2_K 模型表现更差,这非常有趣。 但需要更多测试才能从此得出任何结论。
语言 (Language)
字谜游戏 (Connections)、错别字校正和电影概要解扰。

在这种情况下,14B Q2_K 模型的性能与 8bit 6bit 模型相同。但是,正如我们稍后将看到的,这几乎没有意义,因为 14b q2 模型在速度上明显不如内存占用相同的 8bit 6bit 模型。
数学 (Math)
高中竞赛题 (AMC12, AIME, USAMO, IMO, SMC) 和更难的 AMPS 问题。

中等程度的量化 (Q6_K, Q4_K_M, Q3_K_M) 保持了相似的性能。 相对于量化程度较低的较小模型,14B Q2_K 没有显示出明显的改进。
推理 (Reasoning)
高级逻辑谜题,包括更难的 Web of Lies 任务和 Zebra Puzzles。

令人惊讶。14B Q2_K 模型大大优于所有 8B 变体,这表明较大的模型在复杂的逻辑推理中能更好地处理重度量化。
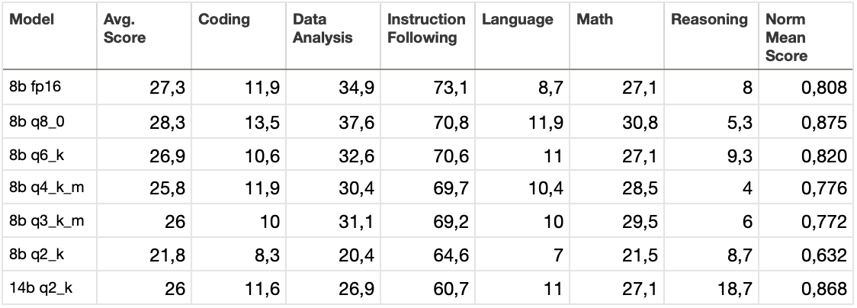
以下是所有测试的汇总表:
此外,我们比较了它们在不同硬件配置下的推理速度。以下是不同设备上的性能比较测试。用于测试的设备:Nvidia RTX 3090, NVIDIA A100-SXM4-40GB, 配备 M2 Pro 和 32 GB 内存的 MacBook Pro 14。

结论 (Conclusions)
根据这些测试结果,可以得出几个明显的结论:
- 16 位精度模型的意义不大: 由于更大的量化模型可以提供更好的结果,因此以 16 位精度运行模型意义不大。
- 4 位量化是平衡之选: 4 位量化格式是最受欢迎的,并且提供了良好的平衡。如果内存充足,增加一些额外的比特可以略微提高准确性。
- 服务器级 GPU 对大模型的优势: 模型越大,配备快速 HBM 内存的服务器级 GPU 相对于消费级 GPU 的优势就越大。
- 14b q2_k 格式的权衡: 14b q2_k 模型与 8b q6_k 模型需要相同的内存量,但运行速度慢得多。同时,除了推理测试外,在所有测试中,它的结果相当甚至略差。然而,这些发现不应在没有额外测试的情况下推断到更大的模型。
量化在优化大型语言模型以进行部署方面起着至关重要的作用。虽然低比特量化显着提高了推理速度并降低了内存需求,但它也带来了准确性方面的权衡。