OPENAI O3 在 ARC-AGI-PUB 中取得突破性的高分
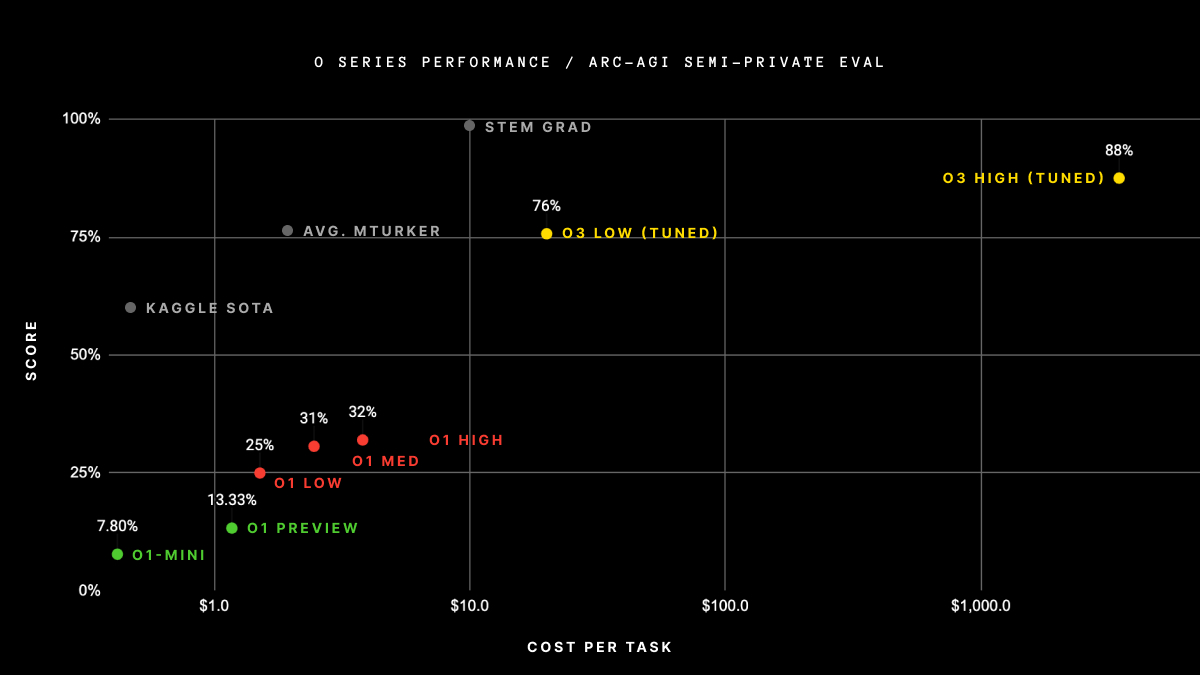
OpenAI 的新 o3 系统——基于 ARC-AGI-1 公共训练集训练——在公开排行榜上声明的$10k 计算限制下,于半私有评估集上取得了突破性的 75.7%得分。高计算量(172 倍)的 o3 配置则达到了 87.5%。
这是 AI 能力的一次令人惊讶且重要的阶跃式提升,展示了 GPT 系列模型前所未有的任务适应能力。回顾一下,从 2020 年 GPT-3 的 0%到 2024 年 GPT-4o 的 5%,ARC-AGI-1 花了 4 年时间。所有关于 AI 能力的直觉都需要为 o3 进行更新。
ARC Prize 的使命超越了我们的首个基准:成为通向 AGI 的北极星。我们很高兴明年能与 OpenAI 团队及其他伙伴合作,继续设计下一代、持久的 AGI 基准。
ARC-AGI-2(相同格式 - 验证对人类简单,对 AI 更难)将与 ARC 大奖 2025 一同推出。我们致力于举办大奖赛,直至产生一个高效、开源且得分达到 85%的解决方案。
请继续阅读完整的测试报告。
OPENAI O3 ARC-AGI 结果
我们针对两个 ARC-AGI 数据集测试了 o3:
- 半私有评估:使用 100 个私有任务来评估过拟合情况
- 公共评估:400 项公共任务
根据 OpenAI 的指示,我们在两种计算水平下进行了测试,样本大小可变:6(高效)和 1024(低效,计算量增加 172 倍)。
以下是结果:
| 设置 | 任务 | 效率 | 得分 | 零售成本 | 示例 | 令牌 | 成本/任务 | 时间/任务 (分钟) |
|---|---|---|---|---|---|---|---|---|
| 半私有 | 100 | 高 | 75.7% | $2,012 | 6 | 33M | $20 | 1.3 |
| 半私有 | 100 | 低 | 87.5% | - | 1024 | 5.7B | - | 13.8 |
| 公开 | 400 | 高 | 82.8% | $6,677 | 6 | 111M | $17 | N/A |
| 公开 | 400 | 低 | 91.5% | - | 1024 | 9.5B | - | N/A |
注意:o3 高计算成本配置的定价和功能可用性尚未确定(TBD),因此暂不可用。其计算量大约是低计算配置的 172 倍。
关于“tuned”的说明:OpenAI 分享了他们训练我们测试的 o3 模型使用了 75% 的公开训练集。他们未提供更多细节。我们尚未测试 ARC-untrained 模型,以了解性能中有多少归因于 ARC-AGI 数据。
由于推理预算的可变性,效率(例如计算成本)现已成为报告性能时的必选指标。我们已记录了总成本和每个任务的成本,作为效率的初步代理指标。作为行业,我们需要确定最能追踪效率的指标,但就方向而言,成本是一个可靠的起点。
75.7%的高效得分符合 ARC-AGI-Pub 的预算规则(成本<$10k),因此有资格在公开排行榜上位列第一!
低效率得分 87.5%相当高昂,但仍表明随着计算量的增加,在新任务上的性能确实有所提升(至少在这个水平上)。
尽管每个任务的成本显著,但这些数字不仅仅是通过将蛮力计算应用于基准测试的结果。OpenAI 的新 o3 模型代表了 AI 适应新任务能力的重大飞跃。这不仅仅是渐进式的改进,而是一个真正的突破,标志着与之前 LLMs 的局限性相比,AI 能力发生了质的转变。o3 是一个能够适应从未遇到过的任务的系统,可以说在 ARC-AGI 领域接近人类水平的表现。
当然,这种普遍性伴随着高昂的成本,目前尚不经济:你可以支付大约 5 美元让人类解决 ARC-AGI 任务(我们知道,我们确实这样做过),而仅消耗几分钱的能源。与此同时,o3 在低计算模式下每任务需要 17-20 美元。但成本效益很可能会在未来几个月到几年内大幅提升,因此你应该计划在相当短的时间内使这些能力与人类工作相竞争。
o3 对 GPT 系列的改进证明了架构的重要性。你无法通过向 GPT-4 投入更多计算资源来获得这些成果。简单地将我们从 2019 年到 2023 年所做的事情进行扩展——采用相同的架构,在更多数据上训练更大的版本——是不够的。进一步的进展需要新的思路。
这是 AGI 吗?
ARC-AGI 作为检测此类突破的关键基准,突显了其在饱和或要求较低的基准无法达到的泛化能力。然而,值得注意的是,ARC-AGI 并非 AGI 的终极测试——正如我们今年反复强调的数十次。它是一个研究工具,旨在将注意力集中在人工智能领域中最具挑战性的未解决问题上,这一角色在过去五年中得到了很好的履行。
通过 ARC-AGI 并不等同于实现 AGI,事实上,我认为 o3 尚未达到 AGI 水平。o3 在某些非常简单的任务上仍然失败,这表明其与人类智能存在根本性差异。
此外,早期数据点表明,即将推出的 ARC-AGI-2 基准测试仍将对 o3 构成重大挑战,即使在高计算量下,其得分可能降至 30%以下(而未经训练的普通人仍能轻松获得超过 95%的分数)。这表明,无需依赖专家领域知识,仍有可能创建具有挑战性且未饱和的基准测试。当为普通人类设计简单但令 AI 难以完成的任务变得不可能时,你就知道 AGI 已经到来。
O3 与旧型号相比有何不同?
为什么 o3 得分比 o1 高这么多?而最初 o1 得分又为何远超 GPT-4o?我认为这一系列结果为正在追求 AGI 的进程提供了极其宝贵的数据点。
我对LLMs的认知模型是,它们作为一个矢量程序的存储库。当被提示时,它们会获取与提示对应的程序,并在当前输入上“执行”它。LLMs是一种通过被动接触人类生成内容来存储和操作数百万个有用小程序的方式。
这种“记忆、提取、应用”范式可以在给定适当训练数据的情况下,实现任意任务的任意技能水平,但它无法适应新颖性或在需要时即时掌握新技能(也就是说,这里并不存在流动智力)。这一点在LLMs在 ARC-AGI 上的低表现中得到了体现,ARC-AGI 是唯一专门设计来衡量对新颖性适应能力的基准测试——GPT-3 得分为 0,GPT-4 接近 0,GPT-4o 达到 5%。即使将这些模型扩展到可能的极限,也无法使 ARC-AGI 的得分接近多年前通过基本暴力枚举所能达到的水平(最高可达 50%)。
要适应新事物,你需要两样东西。首先,你需要知识——一套可重复使用的函数或程序作为基础。LLMs 已经拥有足够多的知识。其次,面对新任务时,你需要有能力将这些函数重新组合成一个全新的程序——一个能够模拟当前任务的程序。这就是程序合成。LLMs 长期以来一直缺乏这一功能。o 系列模型解决了这个问题。
目前,我们只能推测 o3 的具体工作细节。但 o3 的核心机制似乎是在标记空间内进行自然语言程序搜索和执行——在测试时,模型在可能的思维链(CoTs)空间中进行搜索,这些思维链描述了解决任务所需的步骤,这种方式可能与 AlphaZero 风格的蒙特卡洛树搜索颇为相似。在 o3 的情况下,搜索大概是由某种评估模型引导的。值得一提的是,Demis Hassabis 在 2023 年 6 月的采访中暗示,DeepMind 一直在研究这一想法——这项工作已经酝酿了很长时间。
因此,尽管单代LLMs在应对新奇性时挣扎,o3 通过生成并执行自己的程序克服了这一问题,其中程序本身(即 CoT)成为了知识重组的产物。虽然这不是测试时知识重组的唯一可行方法(你也可以进行测试时训练,或在潜在空间中搜索),但根据这些新的 ARC-AGI 数据,它代表了当前最先进的技术水平。
实际上,o3 代表了一种深度学习引导的程序搜索形式。该模型在“程序”空间(在此情况下,即描述解决当前任务步骤的自然语言程序——CoTs 的空间)中进行测试时搜索,由深度学习先验(基础 LLM)引导。解决单个 ARC-AGI 任务最终需要消耗数千万个令牌并耗费数千美元的原因在于,这一搜索过程必须探索程序空间中的大量路径——包括回溯。
然而,这里发生的事情与我之前将“深度学习引导的程序搜索”描述为通向 AGI 的最佳路径时所指的,存在两个显著差异。关键在于,o3 生成的程序是自然语言指令(由LLM“执行”),而不是可执行的符号程序。这意味着两件事。首先,它们无法通过执行和对任务的直接评估与现实接触——相反,它们必须通过另一个模型进行适应性评估,而由于缺乏这种基础,在分布外操作时评估可能会出错。其次,系统无法自主获得生成和评估这些程序的能力(就像 AlphaZero 系统可以自学下棋一样)。相反,它依赖于专家标注、人类生成的 CoT 数据。
目前尚不清楚新系统的具体限制是什么,以及它能扩展到何种程度。我们需要进一步的测试来查明。尽管如此,当前的性能表现已是一项显著的成就,并明确证实了在程序空间中进行直觉引导的测试时搜索是一种强大的范式,可以构建能够适应任意任务的 AI 系统。
接下来是什么?
首先,2025 年 ARC 大奖赛推动的开源 o3 复现将对推动研究社区发展至关重要。全面分析 o3 的优势与局限性,对于理解其扩展行为、潜在瓶颈的性质以及预测未来发展可能解锁的能力是必要的。
此外,ARC-AGI-1 现已饱和——除了 o3 的新得分外,事实是,大量低计算量的 Kaggle 解决方案现在在私有评估中可以达到 81% 的得分。
我们即将推出一个新版本——ARC-AGI-2,自 2022 年以来一直在研发中。它承诺对现有技术进行重大重置。我们希望它通过严格、高信号的评估,推动 AGI 研究的边界,揭示当前 AI 的局限性。
我们的早期 ARC-AGI-2 测试表明,它将非常有用且极具挑战性,甚至对 o3 也是如此。当然,ARC Prize 的目标是产生一个高效且开源的解决方案,以赢得大奖。我们目前计划在 2025 年 ARC Prize(预计在第一季度末)发布时推出 ARC-AGI-2。
展望未来,ARC Prize 基金会将继续设立新的基准,以引导研究者关注通向 AGI 之路上的最棘手未解难题。我们已着手开发第三代基准,该基准完全脱离了 2019 年 ARC-AGI 的格式,并融入了一些令人振奋的新思路。
参与其中:开源分析
今天,我们还发布了高计算量 o3 测试的数据(结果、尝试和提示),并希望您能协助分析这些结果。
特别是,我们对 o3 在大量计算下仍无法解决的约 9%的公共评估任务感到非常好奇,这些任务对人类来说却很简单。
建议分析:
- o3 解决了哪些任务的特性?哪些任务无法解决?
- 您将如何量化 o3 未解决的任务属性?超越描述性统计(网格大小、颜色数量等)。
- 你能为任务分配一个“难度评分”吗?这与 o3 的表现有关联吗?
- 如果你要创建新任务,你会针对哪些属性来使它们对 o3 来说更容易或更困难?
- 我们邀请社区帮助我们评估已解决和未解决任务的特征。
为了激发您的灵感,以下是 3 个未被高计算量 o3 解决的任务示例。
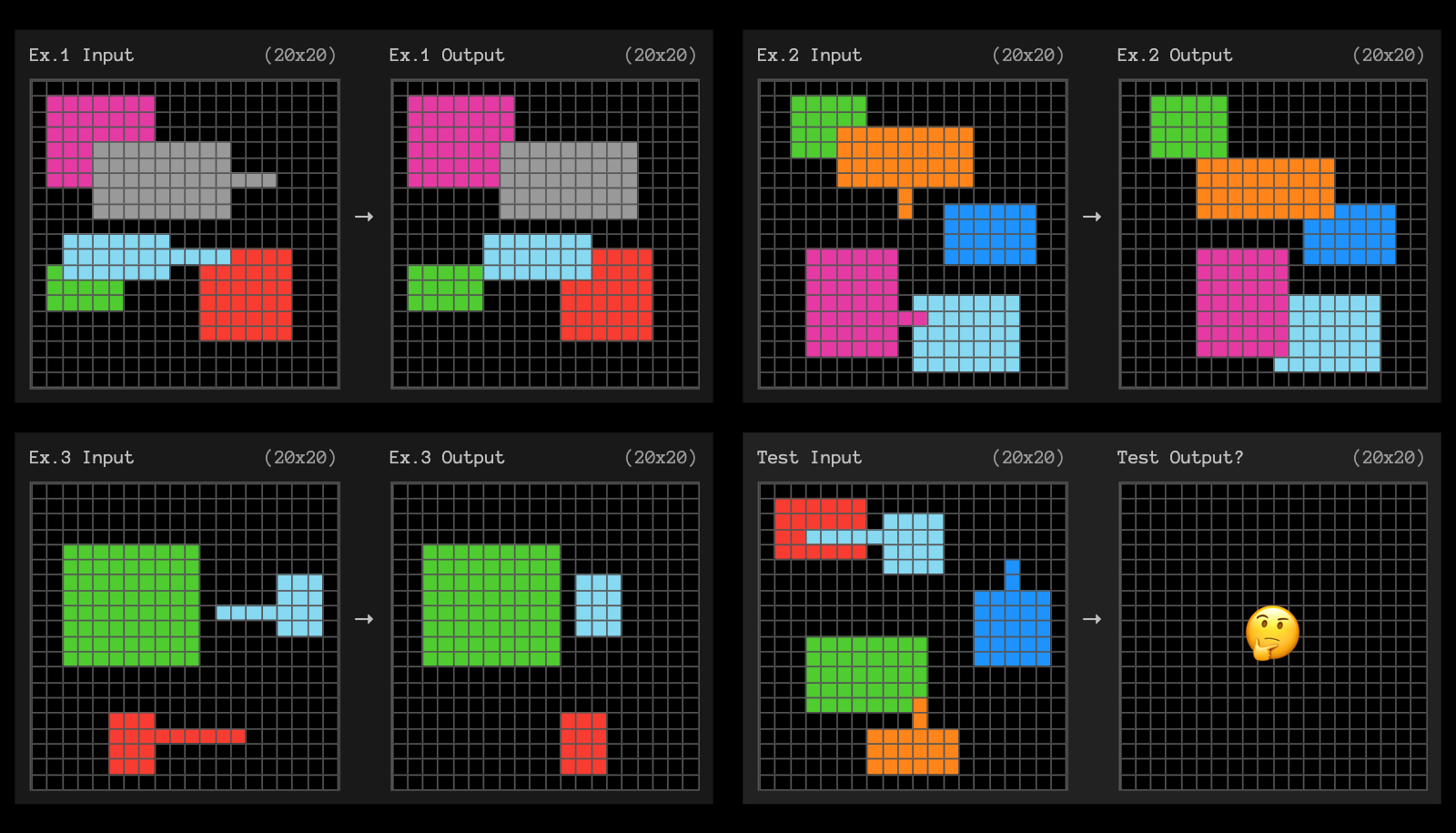
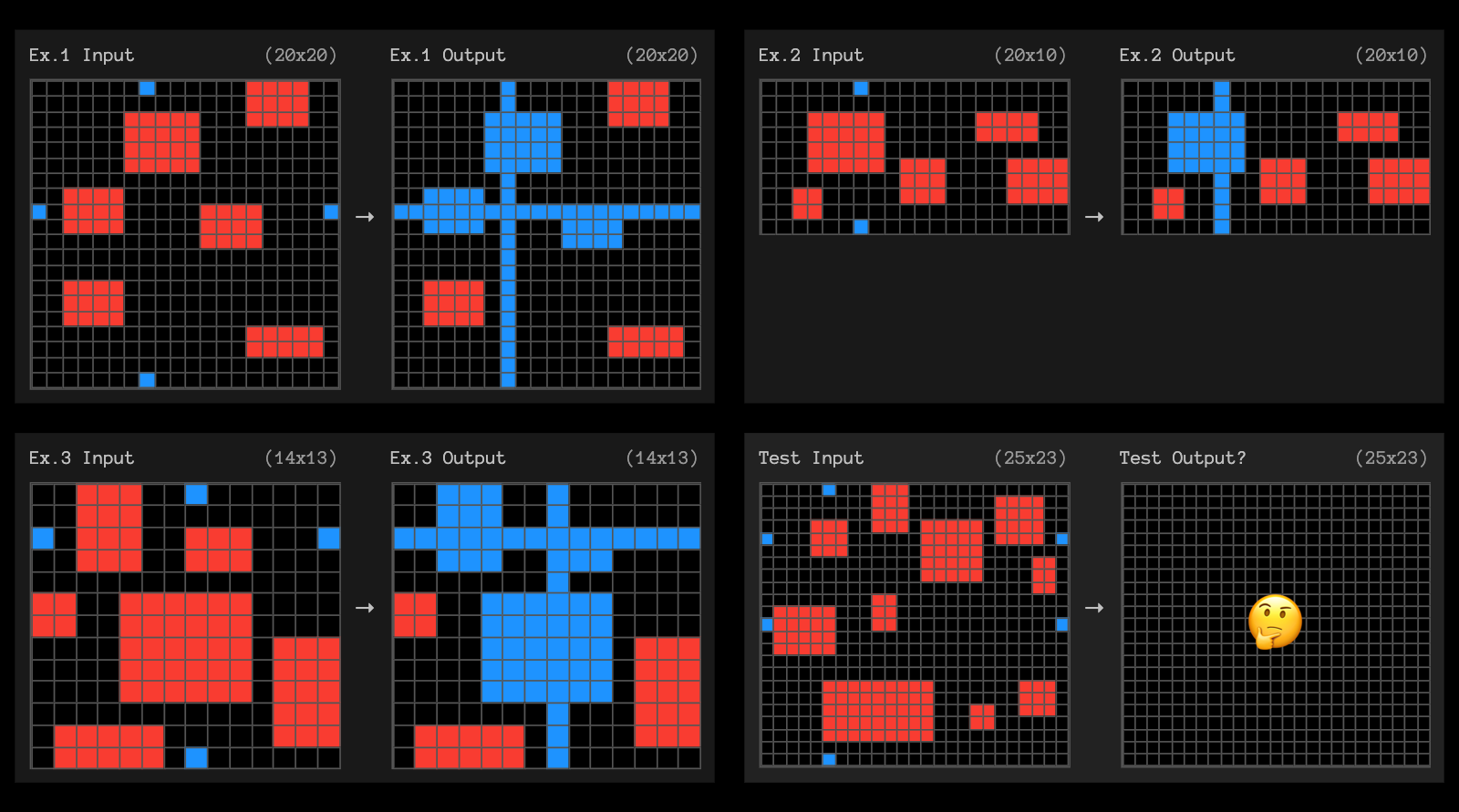

我们也在 Discord 上创建了一个名为 oai-analysis 的新频道,非常希望在那里听到您的分析和见解。或者在 X/Twitter 上@arcprize 联系我们。
结论
总而言之——o3 代表了一个显著的飞跃。它在 ARC-AGI 上的表现突显了在适应性和泛化能力方面的真正突破,这是其他基准测试无法如此明确展现的。
o3 解决了LLM范式的根本局限——测试时无法重组知识——并通过一种LLM引导的自然语言程序搜索来实现这一点。这不仅仅是渐进式的进步,而是开辟了新的领域,需要科学界的认真关注。