Open R1 - 复现 Deepseek-R1
DeepSeek-R1 的完全开源复现。让我们一起构建它!
概述
本仓库的目标是构建 R1 管线中缺失的部分,以便所有人都能复现并在此基础上进行构建。该项目设计简洁,主要包含以下内容:
src/open_r1包含训练和评估模型以及生成合成数据的脚本:grpo.py: 在给定数据集上使用 GRPO 训练模型。sft.py: 在数据集上对模型进行简单的 SFT (监督微调)。evaluate.py: 在 R1 基准上评估模型。generate.py: 使用 Distilabel 从模型生成合成数据。
Makefile包含一个易于运行的命令,用于 R1 管线中的每个步骤,利用上述脚本。
计划
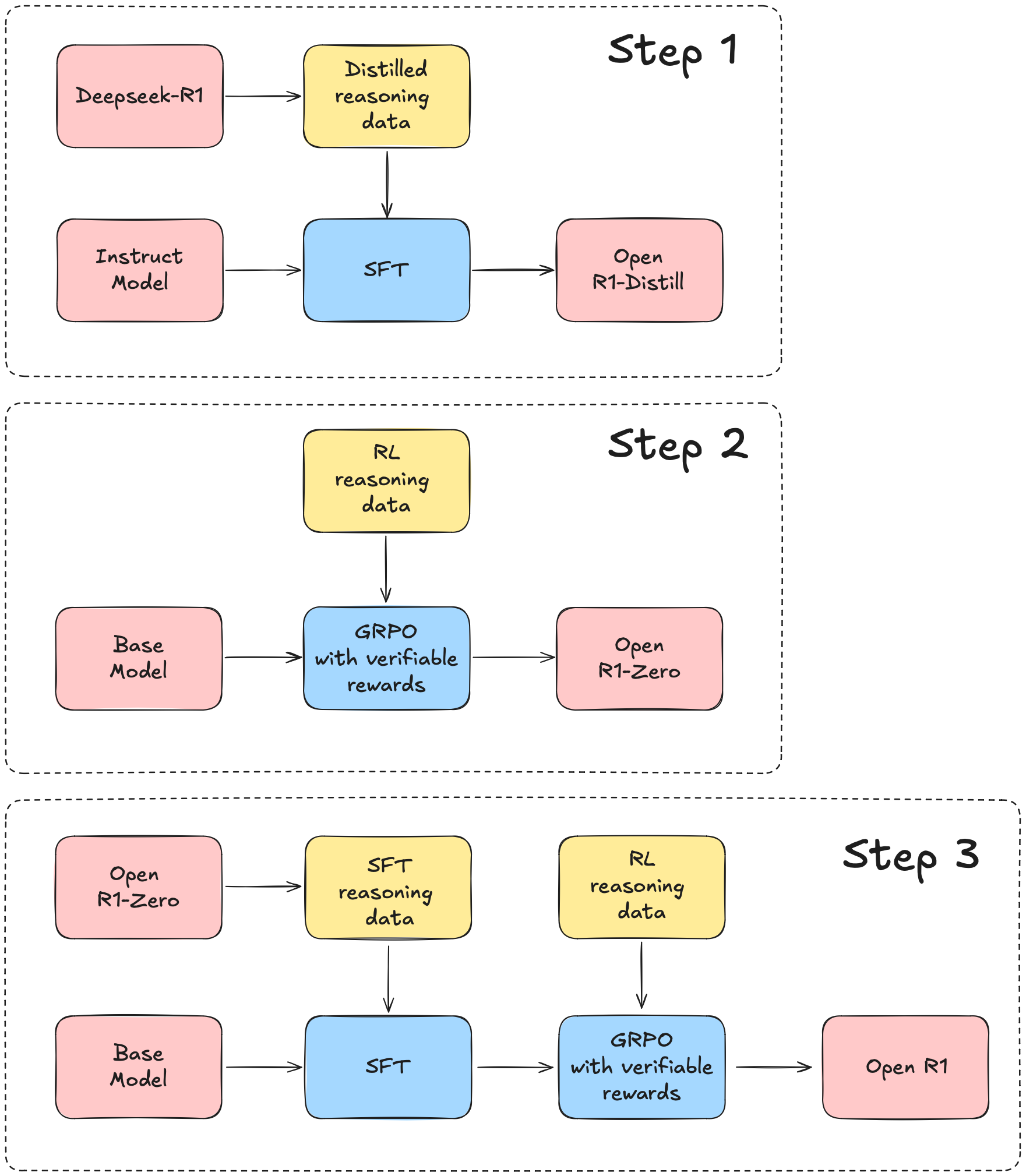
我们将使用 DeepSeek-R1 技术报告 作为指南,该报告大致可以分为三个主要步骤:
- 步骤 1:通过从 DeepSeek-R1 提炼高质量语料库来复现 R1-Distill 模型。
- 步骤 2:复现 DeepSeek 用于创建 R1-Zero 的纯 RL (强化学习) 管线。这可能需要策划新的、大规模的数据集用于数学、推理和代码。
- 步骤 3:展示我们可以通过多阶段训练从基础模型过渡到 RL 调优模型。
安装
要运行此项目中的代码,首先,创建一个 Python 虚拟环境,例如使用 Conda:
conda create -n openr1 python=3.11 && conda activate openr1
接下来,安装 vLLM:
pip install vllm==0.6.6.post1
# 对于 HF (集群仅有 CUDA 12.1)
pip install vllm==0.6.6.post1 --extra-index-url https://download.pytorch.org/whl/cu121
这也会安装 PyTorch v2.5.1,使用此版本非常重要,因为 vLLM 二进制文件是为此版本编译的。 然后,您可以通过 pip install -e .[LIST OF MODES] 为您的特定用例安装其余依赖项。 对于大多数贡献者,我们建议:
pip install -e ".[dev]"
接下来,登录您的 Hugging Face 和 Weights and Biases 帐户,如下所示:
huggingface-cli login
wandb login
最后,检查您的系统是否安装了 Git LFS,以便您可以加载模型/数据集并将其推送到 Hugging Face Hub:
git-lfs --version
如果未安装,请运行:
sudo apt-get install git-lfs
训练模型
我们支持使用 DDP 或 DeepSpeed ZeRO-2 和 ZeRO-3 训练模型。 要在方法之间切换,只需更改 configs 中 accelerate YAML 配置的路径。
[!NOTE] 以下训练命令配置为 8 个 H100 (80GB) 的节点。 对于不同的硬件和拓扑,您可能需要调整批次大小和梯度累积步数。
SFT
要在从 DeepSeek-R1 提炼的数据集上运行 SFT,该数据集带有推理轨迹,例如 Bespoke-Stratos-17k,请运行:
accelerate launch --config_file=configs/zero3.yaml src/open_r1/sft.py \
--model_name_or_path Qwen/Qwen2.5-Math-1.5B-Instruct \
--dataset_name HuggingFaceH4/Bespoke-Stratos-17k \
--learning_rate 2.0e-5 \
--num_train_epochs 1 \
--packing \
--max_seq_length 4096 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 4 \
--gradient_checkpointing \
--bf16 \
--logging_steps 5 \
--eval_strategy steps \
--eval_steps 100 \
--output_dir data/Qwen2.5-1.5B-Open-R1-Distill
要启动 Slurm 作业,请运行:
sbatch --output=/path/to/logs/%x-%j.out --err=/path/to/logs/%x-%j.err slurm/sft.slurm {model} {dataset} {accelerator}
此处 {model} 和 {dataset} 指的是 Hugging Face Hub 上的模型和数据集 ID,而 {accelerator} 指的是 configs 中 🤗 Accelerate 配置的选择。
GRPO
accelerate launch --config_file configs/zero3.yaml src/open_r1/grpo.py \
--output_dir DeepSeek-R1-Distill-Qwen-7B-GRPO \
--model_name_or_path deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--dataset_name AI-MO/NuminaMath-TIR \
--max_prompt_length 256 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--logging_steps 10 \
--bf16
评估模型
我们使用 lighteval 来评估模型,自定义任务在 src/open_r1/evaluate.py 中定义。 对于适合单个 GPU 的模型,请运行:
MODEL=deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
MODEL_ARGS="pretrained=$MODEL,dtype=float16,max_model_length=32768,gpu_memory_utilisation=0.8"
TASK=aime24
OUTPUT_DIR=data/evals/$MODEL
lighteval vllm $MODEL_ARGS "custom|$TASK|0|0" \
--custom-tasks src/open_r1/evaluate.py \
--use-chat-template \
--system-prompt="Please reason step by step, and put your final answer within \boxed{}." \
--output-dir $OUTPUT_DIR
要提高跨多个 GPU 的吞吐量,请使用 数据并行,如下所示:
NUM_GPUS=8
MODEL=deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
MODEL_ARGS="pretrained=$MODEL,dtype=float16,data_parallel_size=$NUM_GPUS,max_model_length=32768,gpu_memory_utilisation=0.8"
TASK=aime24
OUTPUT_DIR=data/evals/$MODEL
lighteval vllm $MODEL_ARGS "custom|$TASK|0|0" \
--custom-tasks src/open_r1/evaluate.py \
--use-chat-template \
--system-prompt="Please reason step by step, and put your final answer within \boxed{}." \
--output-dir $OUTPUT_DIR
对于需要在 GPU 之间分片的的大型模型,请使用 张量并行 并运行:
NUM_GPUS=8
MODEL=deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
MODEL_ARGS="pretrained=$MODEL,dtype=float16,tensor_parallel_size=$NUM_GPUS,max_model_length=32768,gpu_memory_utilisation=0.8"
TASK=aime24
OUTPUT_DIR=data/evals/$MODEL
export VLLM_WORKER_MULTIPROC_METHOD=spawn
lighteval vllm $MODEL_ARGS "custom|$TASK|0|0" \
--custom-tasks src/open_r1/evaluate.py \
--use-chat-template \
--system-prompt="Please reason step by step, and put your final answer within \boxed{}." \
--output-dir $OUTPUT_DIR
数据生成
从小型提炼的 R1 模型生成数据
以下示例可以在 1xH100 上运行。 首先安装以下依赖项:
pip install "distilabel[vllm]>=1.5.2"
现在将以下代码段保存到名为 pipeline.py 的文件中,并使用 python pipeline.py 运行。它将为 10 个示例中的每一个生成 4 个 generations (将仓库的用户名更改为您的组织/用户名):
from datasets import load_dataset
from distilabel.models import vLLM
from distilabel.pipeline import Pipeline
from distilabel.steps.tasks import TextGeneration
prompt_template = """\
You will be given a problem. Please reason step by step, and put your final answer within \boxed{}:
{{ instruction }}""" # 你将获得一个问题。请逐步推理,并将最终答案放在 \boxed{} 中:{{ instruction }}
dataset = load_dataset("AI-MO/NuminaMath-TIR", split="train").select(range(10))
model_id = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B" # Exchange with another smol distilled r1 # 替换为另一个小型提炼的 r1
with Pipeline(
name="distill-qwen-7b-r1",
description="A pipeline to generate data from a distilled r1 model", # 从提炼的 r1 模型生成数据的管线
) as pipeline:
llm = vLLM(
model=model_id,
tokenizer=model_id,
extra_kwargs={
"tensor_parallel_size": 1,
"max_model_len": 8192,
},
generation_kwargs={
"temperature": 0.6,
"max_new_tokens": 8192,
},
)
prompt_column = "problem"
text_generation = TextGeneration(
llm=llm,
template=prompt_template,
num_generations=4,
input_mappings={"instruction": prompt_column} if prompt_column is not None else {}
)
if __name__ == "__main__":
distiset = pipeline.run(dataset=dataset)
distiset.push_to_hub(repo_id="username/numina-deepseek-r1-qwen-7b")
查看 HuggingFaceH4/numina-deepseek-r1-qwen-7b 的示例数据集。
从 DeepSeek-R1 生成数据
为了运行更大的 DeepSeek-R1,我们使用了 2 个节点,每个节点 8xH100,使用本仓库中 slurm/generate.slurm 中的 slurm 文件。 首先,安装依赖项:
(目前我们需要安装 vllm dev wheel,它 修复了 R1 cuda graph capture)
pip install https://wheels.vllm.ai/221d388cc5a836fa189305785ed7e887cea8b510/vllm-1.0.0.dev-cp38-abi3-manylinux1_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu121
pip install "distilabel[vllm,ray,openai]>=1.5.2"
然后,将 generate.slurm 文件放在与 src/open_r1/generate.py 相同的级别(它将尝试在相对路径中运行该文件),并运行以下命令:
sbatch generate.slurm \
--hf-dataset AI-MO/NuminaMath-TIR \
--temperature 0.6 \
--prompt-column problem \
--model deepseek-ai/DeepSeek-R1 \
--hf-output-dataset username/r1-dataset