AI 角色扮演在游戏中的应用:终极指南

人工智能 (AI) 角色扮演在游戏中的应用彻底革新了游戏行业,为全球玩家提供了无与伦比的体验。AI 技术的整合不仅增强了游戏玩法,还改变了开发者创建沉浸式游戏环境的方式。 预计市场规模将增长45 亿美元,复合年增长率 (CAGR) 高达 24.65%,AI 在游戏中的重要性是不容置疑的。这篇博客深入探讨了 AI 角色扮演应用领域,探索它们的影响和未来趋势。
人工智能 (AI) 角色扮演在游戏中的应用彻底革新了游戏行业,为全球玩家提供了无与伦比的体验。AI 技术的整合不仅增强了游戏玩法,还改变了开发者创建沉浸式游戏环境的方式。 预计市场规模将增长45 亿美元,复合年增长率 (CAGR) 高达 24.65%,AI 在游戏中的重要性是不容置疑的。这篇博客深入探讨了 AI 角色扮演应用领域,探索它们的影响和未来趋势。
我第一次试用 Character AI 时,我的机器人听起来像是卡在了永无止境的客户服务循环中——真的不骗你。
我当时都等着它在对话结束时给我一个 “满意度调查” 了。😂

但是,嘿,知道如何在 Character AI 上进行角色扮演并不是什么神秘的艺术。
在这份循序渐进的指南中,我将倾囊相授我是如何扭转局面的,帮助你打造不仅仅是代码和字节的 AI 角色……
我说的是 史诗般、引人入胜的个性,这将给你带来 绝佳的 AI 角色扮演体验。
无论你是在寻找一丝幽默、一点性感,还是背脊发凉的感觉,Character AI 都能满足你。
创建你的第一个角色可能看起来令人生畏,但请别担心 - 这是一个面向完全初学者的指南,将涵盖 Agnai 上角色创建过程的所有部分,以及角色卡中的每个字段。在阅读完本文后,你应该对角色创建的工作原理有一个基本的了解,并对这个过程有足够的认识,从而能够轻松地开始。
一个使用 Verilog 实现的极简 GPU,为了从零开始学习 GPU 的工作原理而优化设计。
使用少于 15 个完全注释的 Verilog 文件构建,包含完整的架构和 ISA 文档,可工作的矩阵加法/乘法内核,以及对内核仿真和执行跟踪的完整支持。

Open R1 项目已经进行了两周,该项目旨在重建 DeepSeek R1 中缺失的部分——特别是训练流程和合成数据。
在这篇文章中,我们很高兴分享 OpenR1-Math-220k 的构建成果:这是我们首个大规模数学推理数据集!
我们还将关注社区在策划用于微调的小型、高质量数据集方面的一些令人兴奋的进展,以及关于如何在训练时和推理时控制推理模型的思维链长度的见解。
让我们深入了解一下!

自从 DeepSeek R1 发布以来已经过去了两周,自从我们启动 open-r1 项目来复现缺失的部分(即训练流程和合成数据)以来也仅仅过去了一周。这篇文章总结了:
它既可以作为项目的更新,也可以作为围绕 DeepSeek-R1 的有趣资源的集合。
大语言模型 (LLM) 的强大能力毋庸置疑,但其庞大的参数量也带来了巨大的计算资源需求。如何在有限的硬件条件下,例如单张消费级显卡 T4 上,高效地进行大模型微调,成为了许多开发者关注的焦点。
本文将基于一个实用的 Notebook 示例,深入探讨如何使用 GRPO (Gradient Ratio Policy Optimization) 算法,在单张 T4 GPU 上对 Qwen2.5-0.5B 这一开源大模型进行全参数微调。我们将详细解析代码,并解释背后的优化策略,帮助读者理解如何在资源受限的环境下也能玩转大模型微调。
最近,我尝试在本地运行使用 Qwen 7B 蒸馏的 DeepSeek R1,而没有使用任何 GPU。我所有的 CPU 核心和线程都被推到了极限,温度达到了最高的 90 摄氏度 (Ryzen 5 7600)。
嘿,各位技术探索者们!你们有没有听说 Google 令人难以置信的 AI 工具的最新消息? 如果你和我一样,可能正渴望深入探索和体验最新最棒的 AI 技术,但也许你也在想,“这会花费我一大笔钱吗?”
好消息是!Google 实际上是在免费赠送 AI 王国的钥匙,通过其 Gemini 2.0 Flash 模型和 Google AI Studio。 最棒的是什么?你可以完全 免费 开始使用。 是的,你没听错!
在本文中,我们将介绍如何从 HuggingFace 选择任何现成的模型并在 Google Collaboratory 上托管它。本文假设您熟悉 Jupyter Notebook,如果您不熟悉,可以在此处轻松学习。最终的 Jupyter Notebook 在文章底部。
Google Colab 为运行机器学习模型和诸如 Ollama 这样的工具提供了绝佳的环境。虽然 Colab 提供了慷慨的免费层级,但我们需要采取一些额外的步骤来确保我们能够有效地运行 Ollama。 让我们逐步完成这个过程。
几天前,Andrej Karpathy 发布了一个名为 “深入探讨类 ChatGPT 的 LLM” 的 视频。这是一个信息金矿,但时长也达到了 3 小时 31 分钟。我观看了完整视频并做了大量笔记,所以我想为什么不为那些想要获取要点而又不想投入大量时间的人整理一个 TL;DR(太长不看)版本呢。
我已经完全解开了 Q* 的谜团:它是一个用于 LLM 的新型基础模块,一个文本条件的空间计算机模型。
在此文中,你可以看到一个为路径寻找训练的模型。这些模型被称为神经元胞自动机 (Neural Cellular Automatons, NCA),而 Q* 是它的基础模型版本 + Q-learning(强化学习)。
它之所以被称为 Q*,很可能是因为它受到了这项关于路径寻找的初步研究的启发,如这里所示,而 Q 则是因为它集成了 Q-learning 作为其训练方法的一部分。
与为单一任务训练不同,你可以对 NCA 进行文本条件设定,并使用今天的 O1/R1 来生成一个庞大的“数据集生成器”库,用于各种谜题,并带有难度参数以进行渐进式训练。
那么这实际上是如何运作的呢?
考虑以下文件:
// demo.mts
function main(message: string): void {
console.log('Message: ' + message);
}
main('Hello!');
现在我们可以像这样运行它:
node demo.mts
DeepSeek-R1 的完全开源复现。让我们一起构建它!
我们很高兴推出 Sky-T1-32B-Flash,我们更新的推理语言模型,它显著减少了过度思考,在具有挑战性的问题上将推理成本降低高达 57%。 此增强在数学、编码、科学和常识等领域降低了生成长度,同时保持了准确性,并且根据 Lambda Cloud 定价,使用 8xH100 仅需 275 美元即可完成完整的训练方案。 为了促进透明度和协作,我们开源了完整的 pipeline——从数据生成和预处理到偏好优化和评估脚本——并公开提供模型权重和数据。
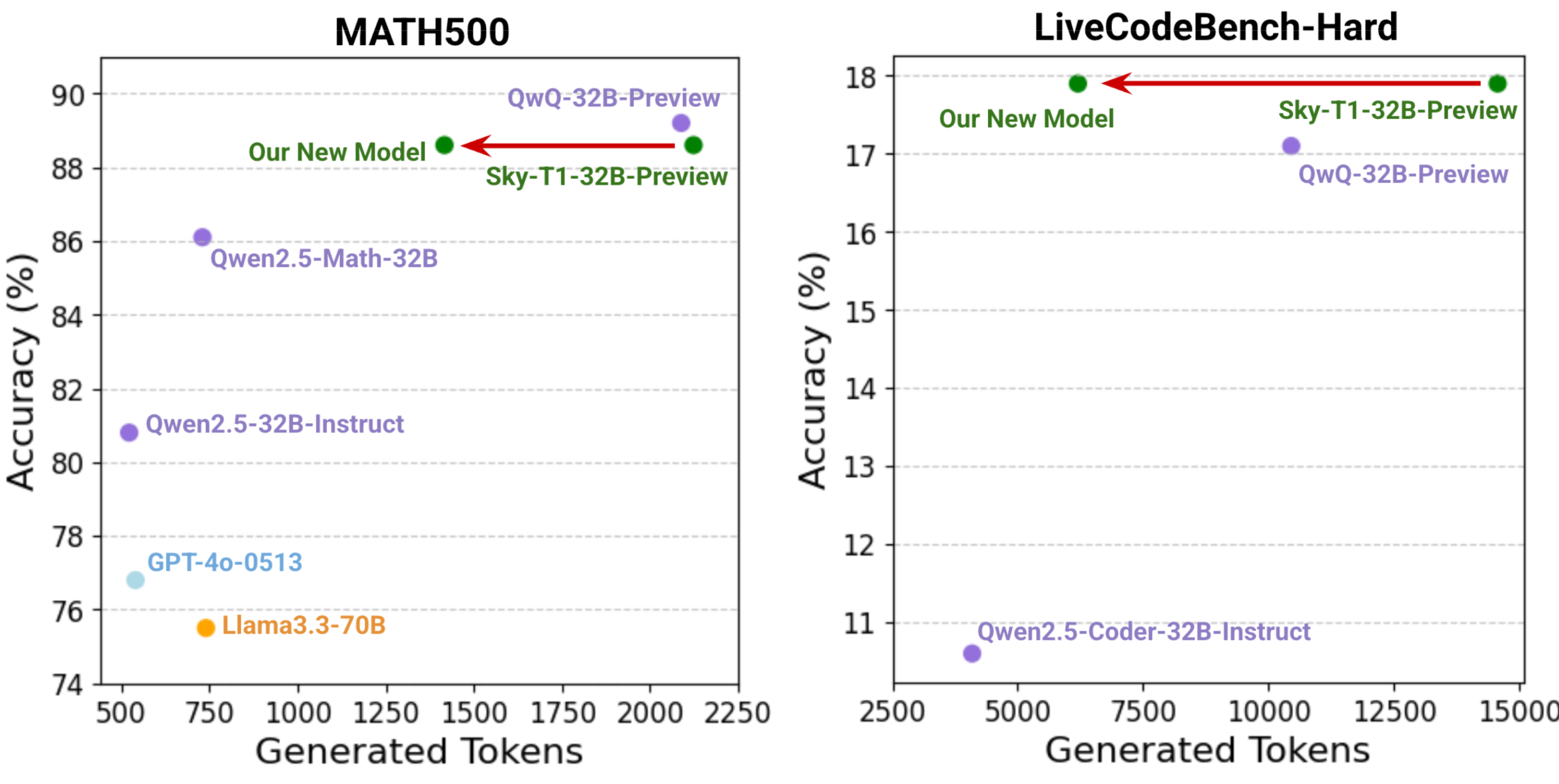 图 1: 我们的新模型在具有挑战性的 benchmarks 上保持强大性能的同时,显著减少了生成的 token 长度。
图 1: 我们的新模型在具有挑战性的 benchmarks 上保持强大性能的同时,显著减少了生成的 token 长度。
是否曾经对深度学习的术语感到不知所措?你不是一个人!这个领域充满了强大的概念,但记住每个术语可能具有挑战性。
本词汇表旨在弥合这一差距。在本文的后续内容中,我们将探讨 100 个重要的深度学习术语,使复杂的概念变得平易近人,并使您能够驾驭这个激动人心的领域。
那么,让我们直接进入文章,了解深度学习术语吧!
人工智能研究 70 年来最大的教训是,利用计算的通用方法最终是最有效的,而且优势巨大。 究其根本原因在于摩尔定律,或者更确切地说,是其计算单位成本持续呈指数级下降的普遍规律。 大多数人工智能研究都是在假设代理可用的计算力是恒定的情况下进行的(在这样的情况下,利用人类知识将是提高性能的唯一方法之一),但是,在比典型的研究项目稍长的时间内,可用的计算力不可避免地会大幅增加。 为了寻求在短期内有所作为的改进,研究人员试图利用他们对领域的人类知识,但从长远来看,唯一重要的是利用计算。 这两者不必相互冲突,但实际上它们往往会相互冲突。 花费在其中一种方法上的时间就不是花费在另一种方法上的时间。 人们在心理上会承诺投资于一种或另一种方法。 并且,基于人类知识的方法往往会使方法复杂化,使其不太适合利用通用方法来发挥计算能力。 人工智能研究人员迟迟才认识到这个痛苦的教训,这样的例子有很多,回顾一些最突出的例子是很有启发意义的。
你已经掌握了 Python 和 NumPy。你可以熟练操作数组、处理数据并自动化任务。但当你看到“Transformer”“反向传播”“GAN”这些术语时,可能会想:如何在编程和深度学习之间架起桥梁?