无服务器到单体应用 – 无服务器爱好者应该担心吗?
亚马逊的Prime Video Tech博客最近发布了一篇文章,引起了一些互联网的关注。本文探讨了一个团队,该团队能够通过从无服务器迁移到“单体应用式”架构,将其基础架构成本降低多达 90%。
并非每天都会听到从无服务器迁移到单体应用式架构的消息。所以理所当然地,这篇文章已经得到了不少第二眼。不过,有些观点充其量是可疑的,声称“看,即使是亚马逊也说无服务器很糟糕!
那是。。。。不是他们所说的一切,也不应该成为你的主要收获。因此,让我们深入研究这篇文章,了解为什么它会大惊小怪。
在这篇文章中,我们将研究:
- 团队试图解决的问题以及最初的基于无服务器的方法
- 采用“单体应用式”架构的第二次迭代。
- 为什么在这种情况下从无服务器到“单体应用式”是正确的举动
请注意,我在这里将单体应用放在引号中。更多内容见第 3 部分。
问题所在
对于某些背景,Prime Video是一种实时流媒体服务,为Amazon Prime订阅者提供100多个频道供您观看。Prime 视频质量和分析团队希望确保向客户提供的视频流质量高,并且没有任何视频或音频问题,例如视频伪影(像素化)、音频-视频同步问题等。该团队希望开发一种机制来持续监视服务中的每个流,以自动评估和检测任何质量问题。
最初,该团队决定利用先前开发的诊断工具。该工具主要利用 AWS Step Functions、Lambda 和 S3 将每个流的音频/视频内容分解为 1 秒的区块,以便更轻松地管理和评估异常情况。
该工具的工作原理是针对每个通道/流连续运行并在一秒钟的段中对其进行评估。对于每个段,都启动了步进函数工作流。步骤函数工作流具有多个状态转换,在将结果保存到 S3 之前执行提取、分析和聚合步骤。
对于那些过去使用过Step Functions的人来说,您可能知道它可能会变得非常昂贵。主要的成本贡献者是状态转换。也就是说,每次您的阶跃函数从一个状态移动到另一个状态时,您都需要支付一定的费用。
在Prime Video的案例中,每个流每秒都会启动一个步进功能。此步骤函数包含多个不同的状态转换来执行其任务。最重要的是,中间帧和音频缓冲区正在转换并存储在 S3 中,这需要 step 函数中的 Lambda 不断向 S3 进行网络调用以获取相关数据。
此体系结构有两个主要问题:成本和可伸缩性。
在成本方面,状态转换和网络调用的数量使得此体系结构无法维护。根据我保守的餐巾纸数学评估,仅步进函数的成本每月就超过 4000 美元。请注意,由于文章中缺乏细节,这种评估非常保守,成本可能要高得多。这甚至没有考虑到 S3 的读写成本,这会进一步放大这个数字。
在可伸缩性方面,Step Functions 有两个重要限制:1) 并发运行的步骤函数工作流的数量,以及 2) 所有状态机中每秒的状态转换数量。这两个限制相结合,使得解决方案无法扩展到需要不断评估的 100+ 个流。Prime Video 团队很快就达到了最大并发限制,最终只能处理预期负载的 5%。很伤心。
下图来自 Prime Video 文章,概述了处理单个流所涉及的架构和多个步骤。
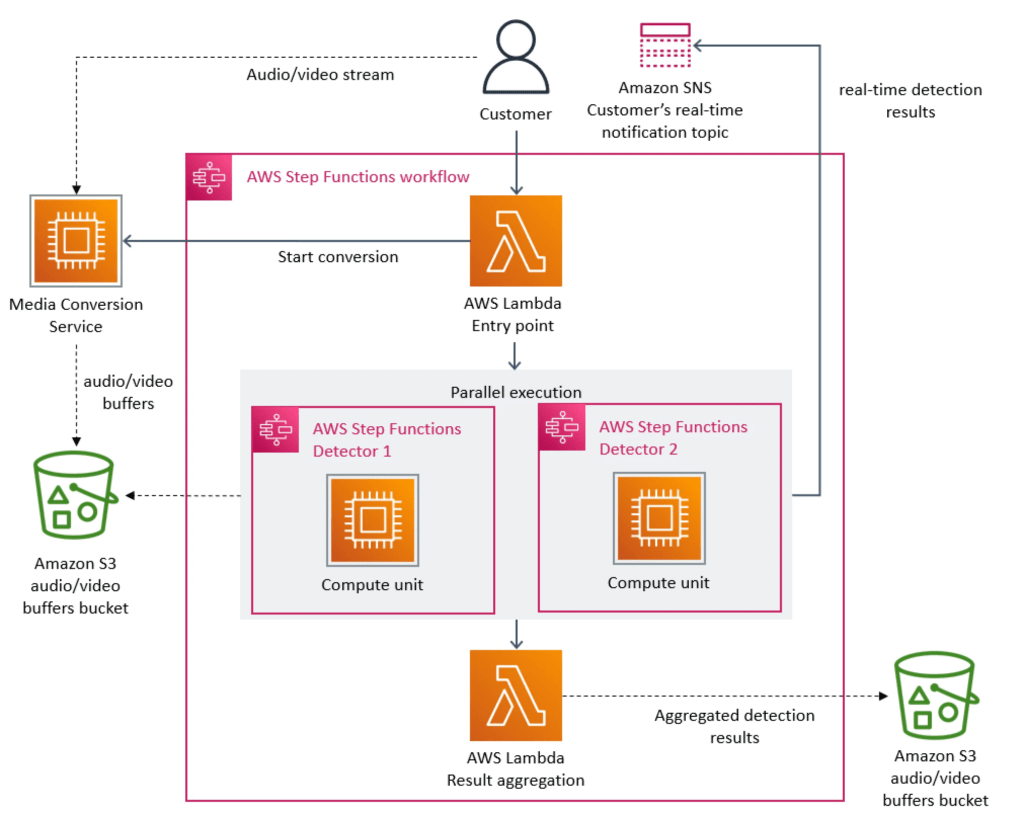
初始 Prime Video 架构利用步进函数进行编排,利用 S3 进行计算,利用 S3 进行中间数据存储。结果是....贵。
鉴于这些成本和扩展瓶颈,该团队重新评估了他们的架构,使其更简单一些,通过避免分布式工作负载组件来优化成本和规模。现在让我们来研究一下。
第二次迭代 – 按比例设计
经过仔细评估,VQA团队意识到Step Function在这种特定规模下不适合这个问题。他们决定选择一种更简单的解决方案,该解决方案依赖于使用弹性容器服务 (ECS) 作为计算层的预置基础设施。
对于跨市场存储,由于对服务进行多个跃点(读取和写入)的成本很高,S3 也被取消了。同样,这并没有给单体应用架构增加太多。
该解决方案涉及在 ECS 任务中本地运行块提取和分析。这样,它不再依赖于步骤功能通过工作流来编排任务,而是从特定的 ECS 任务中串行完成。
该任务将首先执行媒体转换,然后通过多个检测器运行内容进行质量分析来分析每个 1s 块。每个检测器都是独一无二的,因为它使用不同的方法来分析流的质量问题。
借助此架构,不再需要将中间数据存储在 S3 中并在工作流中的特定点获取。它们全部存储在 ECS 任务的本地内存中,并根据需要使用/丢弃。除了摆脱Step Functions之外,这一点确实有助于降低运行服务的成本。
最后,检测器对内容块执行任务后,每个检测器的结果将聚合到 ECS 任务中,并使用一个写入操作保存到 S3。
修改后的体系结构示意图如下所示:
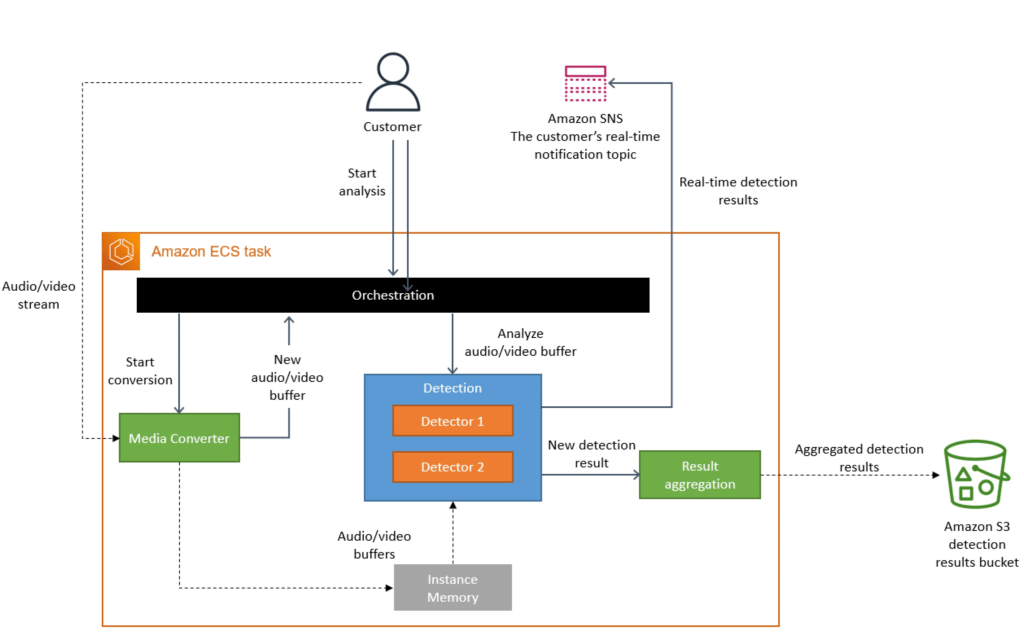
依靠 ECS 任务运行计算的第二次迭代。
敏锐的观察者可能会注意到,这种架构在检测器组件中存在缩放瓶颈。想象一下,光伏团队希望利用一些新方法来检测音频/视频质量。在此体系结构中,这意味着再添加一个检测器,并为每个内容块串行运行它(除了其他检测器之外)。
如果单个任务需要运行的检测器过多,则通过多个检测器运行内容所需的时间将会增加。如果添加的太多,并且检测器之间的操作总和超过 1 秒(块解析速率),则整个工作流将开始落后并且无法恢复。
在Prime Video案例中,确实需要多个探测器,但在处理方面落后不是一种选择。为了缓解这种情况,该团队决定将每个 ECS 任务参数化,以便每个任务都专用于运行少数检测器。然后,团队可以并行启动多个 ECS 任务,每个任务只执行几个检测器。这使他们能够通过将工作负载分解为单独的单元并同时运行它们来水平扩展。
修改后的体系结构如下所示:
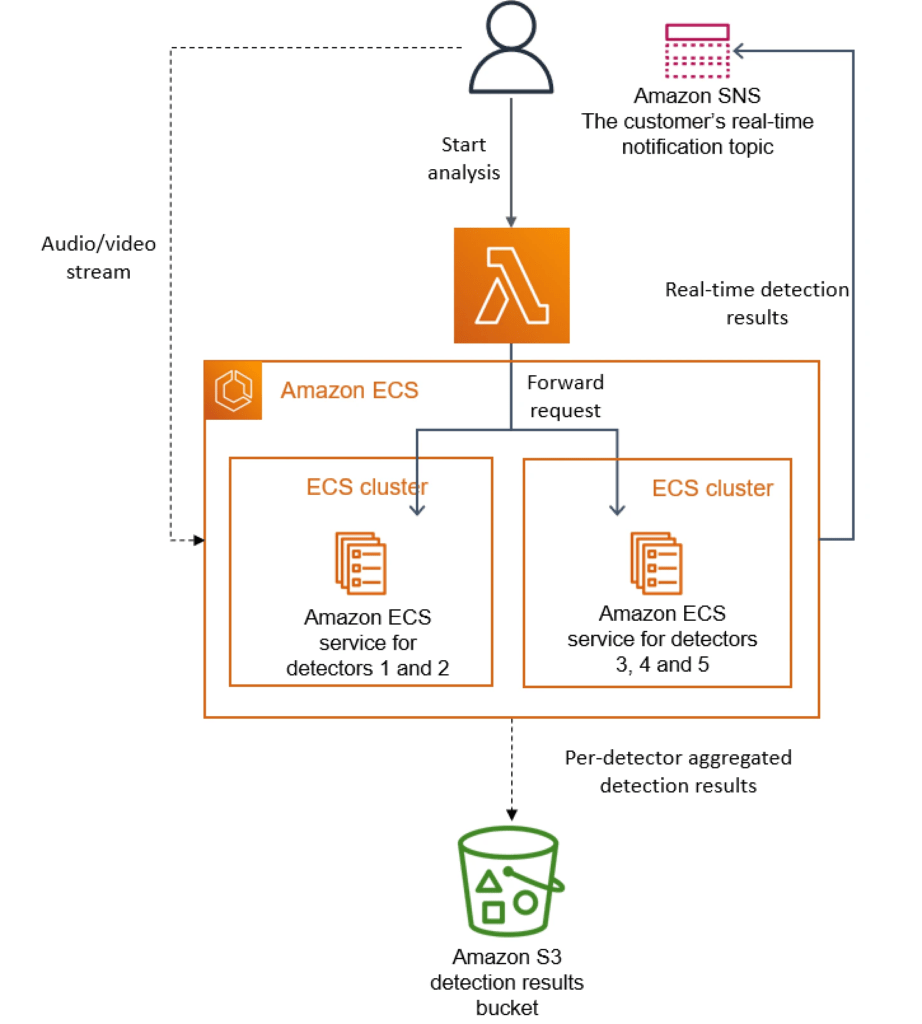
扩展解决方案以添加检测器并行化以扩大规模
通过使用这种修订后的架构,光伏团队现在有一个可扩展且经济高效的解决方案来监控他们的馈电。总而言之,与最初的无服务器迭代相比,他们能够节省 90% 的成本。
这就是风靡互联网的故事。但为什么每个人都吓坏了呢?这种从无服务器到单体的转变是行业的新趋势吗?无服务器爱好者应该担心吗?我说不,原因将在下一节中列出。
为什么从无服务器到“单体应用式”是正确的举措
首先,这种架构不是铁板一块,这是互联网生气的部分原因。当我想到一个单体应用时,我想到的是一个具有许多不同职责的巨型服务。也许它有API,SQS轮询器,为不同的用例做多件事,你明白了。但是架构是否布置在单体应用之上?几乎不。看在上帝的份上,这是一个小型微服务!因此,马上,人们对巨石回归时尚的整个大惊小怪是一个有争议的问题。
其次,原始架构基于一种不是为规模而设计的工具。根据这篇文章,它读起来好像这个工具用于诊断,以对流质量进行临时评估。这意味着它可能不是为规模而设计的,也不是通过正式设计文档/审查的压力测试。如果发生这种情况,任何工厂软件工程师的运行都将能够识别将遇到的明显扩展/成本瓶颈。
最后,我认为光伏团队通过切换到配置基础设施做出了所有正确的举措。他们确定了一个可能成为潜在解决方案的现有工具。在意识到它有一些真正的扩展/成本瓶颈之前,他们试图利用它。在评估情况后,他们调整并重新设计了更强大的解决方案,该解决方案恰好使用了预置的基础架构。这就是软件开发过程的全部内容。
就整个无服务器与单体应用/微服务的争论而言——为什么我们在 2023 年仍然有这个争论?无服务器并不是每个问题的理想选择,这同样适用于单体应用式架构或预配的基础结构。两者都有一席之地,由我们来为工作选择合适的工具。
如果您是构建基于云的现代应用程序的开发人员,请记住仔细分析工作负载的特征,并确定最适合的基础结构。不要仅仅因为某个特定的基础设施或技术很受欢迎而陷入使用这种模式或技术——选择有意义且适用于您的用例的内容。
这就是我的咆哮。我很想听听其他人对这篇文章和随之而来的互联网辩论的看法。在下面的评论中让我知道您的想法。