推测性解码:实现示例指南
LLMs 非常强大,但它们往往有点慢,这在需要速度的场景中并不理想。推测性解码是一种旨在通过更快生成响应而不牺牲质量来加速 LLMs 的技术。
本质上,这是一种在文本生成过程中“提前猜测”的方法,在保持LLMs所期望的准确性和深度的同时,预测可能出现的下一个词语。
在本篇博客中,我将解释什么是推测性解码,它是如何工作的,以及如何使用 Gemma 2 模型来实现它。
什么是推测性解码?
推测性解码通过引入一个更小、更快的模型来加速LLMs,该模型生成初步预测。这个较小的模型,通常称为“草稿”模型,生成一批 Token,主模型LLM可以确认或改进这些 Token。草稿模型作为第一遍,生成多个 Token,从而加快生成过程。
与主模型LLM 顺序生成 Token 不同,草稿模型提供了一组可能的候选者,主模型并行评估它们。这种方法通过卸载初始预测,减轻了主模型LLM 的计算负担,使其能够专注于修正或验证。
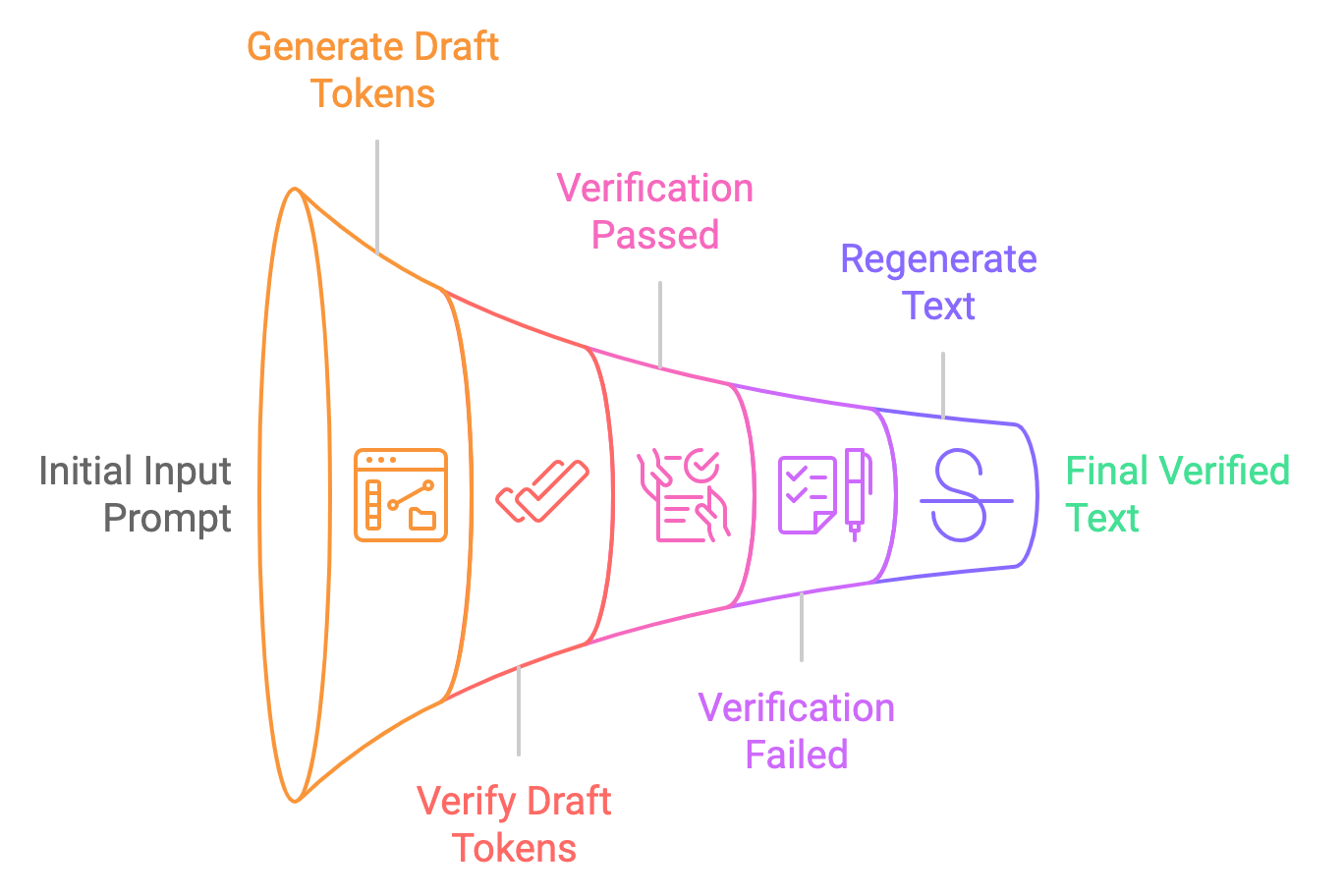
想象一下,这就像一个作家和一个编辑。主要的LLM是作家,能够创作高质量的文本,但速度较慢。一个较小、更快的“草稿”模型充当编辑,快速生成文本的可能延续。然后,主要的LLM评估这些建议,采纳准确的并舍弃其余的。这使得LLM能够同时处理多个标记,从而加快文本生成速度。
让我们将推测性解码的过程分解为简单的步骤:
- 草稿生成:较小的模型(例如,Gemma2-2B-it)根据输入提示生成多个标记建议。这些标记是推测性生成的,意味着模型并不确定它们是正确的,但将它们作为“草稿”标记提供。
- 并行验证:较大的模型(例如,Gemma2-9B-it)并行验证这些 Token,检查其概率是否符合模型学习到的分布。如果这些 Token 被认为是可接受的,它们将被用于最终输出。否则,较大的模型会对其进行修正。
- 最终输出:一旦 Token 被验证(或修正),它们将作为最终输出传递给用户。整个过程比传统的逐个 Token 解码要快得多。
传统解码 vs. 推测性解码
传统的解码过程是逐个处理 Token,导致高延迟,但推测性解码允许较小的模型批量生成 Token,由较大的模型进行验证。这可以将响应时间减少 30-40%,将延迟从 25-30 秒缩短至仅需 15-18 秒。
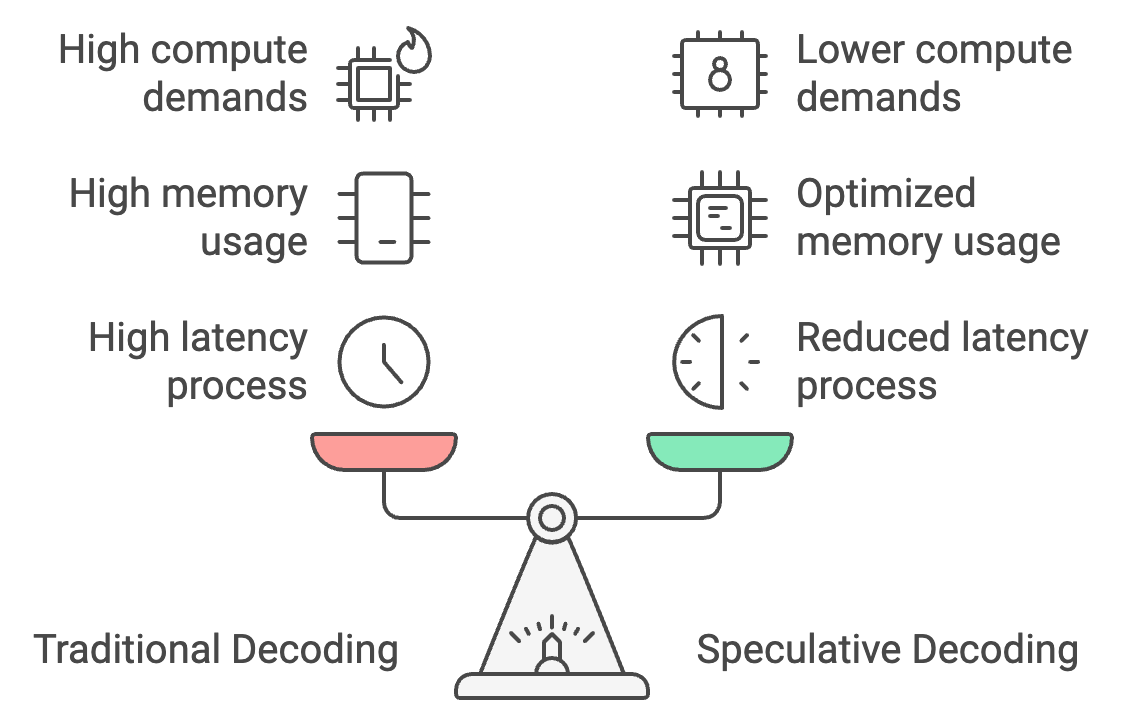
此外,推测性解码通过将大部分 Token 生成转移到较小的模型,优化了内存使用,将内存需求从 26 GB 减少到约 14 GB,从而使设备上的推理更加可行。
最后,它降低了 50%的计算需求,因为较大的模型仅进行验证而非生成 Token,从而在功耗有限的移动设备上实现更流畅的性能,并防止过热。
动手实践:使用 Gemma2 模型进行推测性解码
实现一个使用 Gemma2 模型的推测解码的实践示例。我们将探讨推测解码与标准推理在延迟和性能方面的比较。.
步骤 1:模型和分词器设置
开始之前,导入依赖项并设置种子。
接下来,检查您正在操作的机器上是否可用 GPU。这对于大型模型(如 Gemma 2-9B-it 或 LLama2-13B)尤为必要。
最后,我们加载了小型和大型模型及其分词器。这里,我们使用 Gemma2-2b-it(指令)模型作为草稿模型,并使用 Gemma2-9b-it 模型进行验证。
还有其他几种模型也可以作为替代使用。例如:
- Gemma 7B(主) & Gemma 2B(草稿)
- Mixtral-8x7B(主)与 Mistral 7B(草稿)
- Pythia 12B(主) & Pythia 70M(草稿)
- Llama 2 13B(主) & TinyLlama 1.1B(草稿)
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
# Set Seed
set_seed(42)
# Check if GPU is available
device = "cuda" if torch.cuda.is_available() else "cpu"
# Load the smaller Gemma2 model (draft generation)
small_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b-it", device_map="auto")
small_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it", device_map="auto", torch_dtype=torch.bfloat16)
# Load the larger Gemma2 model (verification)
big_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it", device_map="auto")
big_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", device_map="auto", torch_dtype=torch.bfloat16)
步骤 2:自回归(正常)推理
首先,我们仅对大型模型(Gemma2-9b-it)进行推理并生成输出。开始时,将输入提示进行分词,并将分词结果移动到正确的设备(如果有 GPU 则使用 GPU)。 generate 方法生成模型的输出,最多生成 max_new_tokens 个。然后将结果从分词 ID 解码回人类可读的文本。
def normal_inference(big_model, big_tokenizer, prompt, max_new_tokens=50):
inputs = big_tokenizer(prompt, return_tensors='pt').to(device)
outputs = big_model.generate(inputs['input_ids'], max_new_tokens=max_new_tokens)
return big_tokenizer.decode(outputs[0], skip_special_tokens=True)
步骤 3:推测性解码
接下来,我们尝试推测性解码方法,具体步骤如下:
- 草稿生成:较小的模型根据给定的提示生成文本草稿。
- 验证:较大的模型随后通过计算草稿中每个标记的对数似然来验证草稿。
- 对数似然计算:我们计算平均对数似然,以确定大模型认为小模型的草稿正确的可能性。
def speculative_decoding(small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens=50):
# Step 1: Use the small model to generate the draft
inputs = small_tokenizer(prompt, return_tensors='pt').to(device)
small_outputs = small_model.generate(inputs['input_ids'], max_new_tokens=max_new_tokens)
draft = small_tokenizer.decode(small_outputs[0], skip_special_tokens=True)
# Step 2: Verify the draft with the big model
big_inputs = big_tokenizer(draft, return_tensors='pt').to(device)
# Step 3: Calculate log-likelihood of the draft tokens under the large model
with torch.no_grad():
outputs = big_model(big_inputs['input_ids'])
log_probs = torch.log_softmax(outputs.logits, dim=-1)
draft_token_ids = big_inputs['input_ids']
log_likelihood = 0
for i in range(draft_token_ids.size(1) - 1):
token_id = draft_token_ids[0, i + 1]
log_likelihood += log_probs[0, i, token_id].item()
avg_log_likelihood = log_likelihood / (draft_token_ids.size(1) - 1)
# Return the draft and its log-likelihood score
return draft, avg_log_likelihood
注意:对数似然是模型分配给特定标记序列的概率的对数。在这里,它反映了模型在给定先前标记的情况下,认为标记序列(生成的文本)有效的可能性或“置信度”。
步骤 4:测量延迟
在实现了这两种技术之后,我们可以测量它们各自的延迟。对于推测性解码,我们通过检查对数似然值来评估性能。对数似然值趋近于零,尤其是在负值范围内,表明生成的文本是准确的。
def measure_latency(small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens=50):
# Measure latency for normal inference (big model only)
start_time = time.time()
normal_output = normal_inference(big_model, big_tokenizer, prompt, max_new_tokens)
normal_inference_latency = time.time() - start_time
print(f"Normal Inference Output: {normal_output}")
print(f"Normal Inference Latency: {normal_inference_latency:.4f} seconds")
print("\n\n")
# Measure latency for speculative decoding
start_time = time.time()
speculative_output, log_likelihood = speculative_decoding(
small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens
)
speculative_decoding_latency = time.time() - start_time
print(f"Speculative Decoding Output: {speculative_output}")
print(f"Speculative Decoding Latency: {speculative_decoding_latency:.4f} seconds")
print(f"Log Likelihood (Verification Score): {log_likelihood:.4f}")
return normal_inference_latency, speculative_decoding_latency
这将返回:
- 对数似然(验证得分):-0.5242
- 正常推理延迟:17.8899 秒
- 推测性解码延迟:10.5291 秒(约快 70%)
较低的延迟归功于较小的模型在文本生成上花费的时间更少,而较大的模型仅用于验证生成文本的时间也更少。
在五个提示上测试推测性解码
让我们通过五个提示来比较投机解码与自回归推理:
# List of 5 prompts
prompts = [
"The future of artificial intelligence is ",
"Machine learning is transforming the world by ",
"Natural language processing enables computers to understand ",
"Generative models like GPT-3 can create ",
"AI ethics and fairness are important considerations for "
]
# Inference settings
max_new_tokens = 200
# Initialize accumulators for latency, memory, and tokens per second
total_tokens_per_sec_normal = 0
total_tokens_per_sec_speculative = 0
total_normal_latency = 0
total_speculative_latency = 0
# Perform inference on each prompt and accumulate the results
for prompt in prompts:
normal_latency, speculative_latency, _, _, tokens_per_sec_normal, tokens_per_sec_speculative = measure_latency_and_memory(
small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens
)
total_tokens_per_sec_normal += tokens_per_sec_normal
total_tokens_per_sec_speculative += tokens_per_sec_speculative
total_normal_latency += normal_latency
total_speculative_latency += speculative_latency
# Calculate averages
average_tokens_per_sec_normal = total_tokens_per_sec_normal / len(prompts)
average_tokens_per_sec_speculative = total_tokens_per_sec_speculative / len(prompts)
average_normal_latency = total_normal_latency / len(prompts)
average_speculative_latency = total_speculative_latency / len(prompts)
# Output the averages
print(f"Average Normal Inference Latency: {average_normal_latency:.4f} seconds")
print(f"Average Speculative Decoding Latency: {average_speculative_latency:.4f} seconds")
print(f"Average Normal Inference Tokens per second: {average_tokens_per_sec_normal:.2f} tokens/second")
print(f"Average Speculative Decoding Tokens per second: {average_tokens_per_sec_speculative:.2f} tokens/second")
Average Normal Inference Latency: 25.0876 seconds
Average Speculative Decoding Latency: 15.7802 seconds
Average Normal Inference Tokens per second: 7.97 tokens/second
Average Speculative Decoding Tokens per second: 12.68 tokens/second
这表明推测性解码更为高效,每秒生成的 Token 数多于常规推理。这一改进的原因在于较小的模型处理了大部分文本生成工作,而较大的模型仅限于验证,从而在延迟和内存方面降低了整体计算负载。
凭借这些内存需求,我们可以在边缘设备上轻松部署推测性解码技术,并在聊天机器人、语言翻译器、游戏等设备应用程序上获得加速效果。
量化优化的推测性解码
上述方法虽然高效,但在设备推理时,延迟与内存优化之间存在权衡。为解决这一问题,我们可对小模型和大模型都应用量化技术。你可以尝试仅对大模型进行量化实验,因为小模型本身已占用最少空间。
量化应用于使用 Hugging Face transformers 库中的 BitsAndBytesConfig 配置的小型和大型模型。量化使我们能够显著减少内存使用,并且在许多情况下,通过将模型的权重转换为更紧凑的形式来提高推理速度。
将以下代码片段添加到上述代码中,以观察量化的效果。
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # Enables 4-bit quantization
bnb_4bit_quant_type="nf4", # Specifies the quantization type (nf4)
bnb_4bit_compute_dtype=torch.bfloat16, # Uses bfloat16 for computation
bnb_4bit_use_double_quant=False, # Disables double quantization to avoid additional overhead
)
# Load the smaller and larger Gemma2 models with quantization applied
small_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it", device_map="auto", quantization_config=bnb_config)
big_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", device_map="auto", quantization_config=bnb_config)
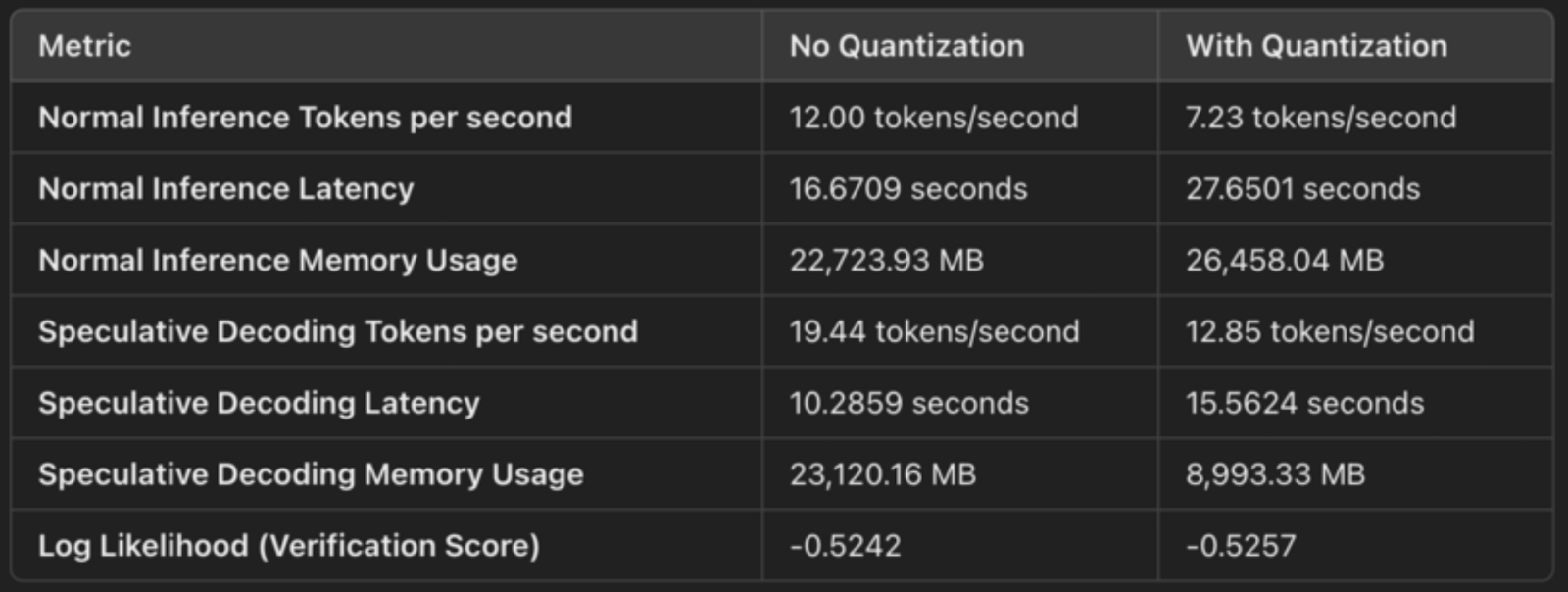
以下是一个快速比较输出,以展示有无量化的情况下推测解码的效果:
4 位量化(权重压缩)
配置中指定 load_in_4bit=True ,这意味着模型的权重从原始的 32 位或 16 位浮点格式量化为 4 位整数。这减少了模型的内存占用。量化压缩了模型的权重,使我们能够更高效地存储和操作它们。以下是具体的内存节省情况:
- 通过将精度从 32 位或 16 位浮点数降低到 4 位整数,每个权重现在占用的空间仅为原始空间的 1/4 或 1/8,显著减少了内存使用。
- 这体现在内存使用上为:
- 正常推理内存使用:26,458 MB
- 推测性解码内存使用量:8,993 MB。
用于计算的 bfloat16(高效利用 Tensor Cores)
配置 bnb_4bit_compute_dtype=torch.bfloat16 指定计算在 bfloat16(BF16)中执行,这是一种更高效的浮点格式。BF16 比 FP16 具有更宽的动态范围,但相比 FP32 占用一半的内存,使其成为精度和性能之间的良好平衡。
使用 BF16,特别是在 NVIDIA GPU(如 A100)上,利用了针对 BF16 操作优化的 Tensor Core。这使得在推理过程中矩阵乘法和其他计算速度更快。
对于推测性解码,我们观察到延迟有所改善:
- 正常推理延迟:27.65 秒
- 推测性解码延迟:15.56 秒
较小的内存占用意味着更快的内存访问和更高效的 GPU 资源利用,从而实现更快的生成速度。
NF4 量化类型(优化精度)
bnb_4bit_quant_type="nf4" 选项指定 Norm-Four 量化(NF4),该量化方法针对神经网络进行了优化。NF4 量化有助于保持模型重要部分的精度,尽管权重以 4 位表示。与简单的 4 位量化相比,这最大限度地减少了模型性能的下降。
NF4 在 4 位量化的紧凑性与模型预测的准确性之间实现了平衡,确保性能接近原始水平的同时大幅降低内存使用。
禁用双重量化
双重量化( bnb_4bit_use_double_quant=False )在 4 位权重之上引入了一个额外的量化层,这可以进一步减少内存使用,但也会增加计算开销。在这种情况下,禁用双重量化以避免减慢推理速度。
推测性解码的应用
推测性解码的潜在应用广泛且令人兴奋。以下是一些示例:
- 聊天机器人和虚拟助手:为了使与人工智能的对话感觉更自然流畅,并实现更快的响应时间。
- 实时翻译:推测性解码减少了实时翻译中的延迟。
- 内容生成:推测性解码加速内容创建。
- 游戏和互动应用:为了提高由 AI 驱动的角色或游戏元素的响应速度,从而获得更沉浸式的体验,推测性解码可以帮助我们实现几乎实时的响应。
推测解码的挑战
尽管推测性解码具有巨大的潜力,但它并非没有挑战:
- 内存开销:维护多个模型状态(用于草稿和主版本LLM)可能会增加内存使用,尤其是在使用较大模型进行验证时。
- 调整草稿模型:选择合适的草稿模型并调整其参数对于在速度和准确性之间找到平衡至关重要,因为过于简单的模型可能导致频繁的验证失败。
- 实现复杂性:实现推测性解码比传统方法更为复杂,需要在小草稿模型和较大验证模型之间进行仔细的同步,以及高效处理错误。
- 解码策略兼容性:推测性解码目前仅支持贪心搜索和采样,限制了其在更复杂的解码策略(如束搜索或多样的采样)中的应用。
- 验证开销:如果较小的草稿模型生成的 Token 频繁未能通过验证,效率提升可能会被削弱,因为较大的模型需要重新生成部分输出,可能会抵消速度上的优势。
- 对批处理的支持有限:推测性解码通常不支持批量输入,这可能会降低其在需要并行处理多个请求的高吞吐量系统中的有效性。
结论
推测性解码是一种强大的技术,有望彻底改变我们与大型语言模型的交互方式。它能够在不降低生成文本质量的情况下,显著加快LLM推理速度。尽管存在一些挑战需要克服,但推测性解码的优势是显而易见的,预计未来几年其应用将不断增长,推动新一代更快速、更灵敏、更高效的 AI 应用的诞生。