在 Google Colab 中试用 VLLM + DeepSeek R1:快速指南
最近,我尝试在本地运行使用 Qwen 7B 蒸馏的 DeepSeek R1,而没有使用任何 GPU。我所有的 CPU 核心和线程都被推到了极限,温度达到了最高的 90 摄氏度 (Ryzen 5 7600)。

我的 CPU 正在运行 ollama deepseek-r1 distilled qwen 7b
我的朋友说,你为什么不使用 Google Colab 呢?因为它给你提供了一个 GPU(免费 3-4 小时)。他一直在使用它来开发 RAG 应用,解析超过 80 页的 PDF,并链接 LLM,因为我们仍然可以“滥用”(使用)google colab。
然后我照做了,我体验了一下 T4 (20 系列) GPU,但有一些注意事项(稍后我会解释,TL:DR 因为它是免费的)。所以我一直在使用它在 Google Colab 中测试 VLLM。使用 FastAPI 和 ngrok 将 API 公开到公共网络(用于测试目的,何乐而不为呢?)。
好的,现在是时候解释一切以及我为什么这么做了。
(警告:这仅用于测试目的)。
PIP (Pip Install Package)。
它允许你安装和管理标准 Python 库中未包含的额外库和依赖项。现在我们将使用 CLI 通过将 ! 传递到 Jupyter Notebook 的代码中来安装它。
!pip install fastapi nest-asyncio pyngrok uvicorn
!pip install vllm
我们将安装 FastAPI、nest-asyncio、pyngrok 和 Uvicorn 作为 Python 服务,它们将处理来自外部来源的请求。VLLM 主要是用于 LLM 推理和服务的库。虽然 Ollama 也是一种选择,但我相信这种方法会更有效。
现在我们将与 VLLM 函数交互。
# 加载并运行模型:
import subprocess
import time
import os
# 在后台启动 vllm 服务器
vllm_process = subprocess.Popen([
'vllm',
'serve', # 子命令必须跟在 vllm 之后
'deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B',
'--trust-remote-code',
'--dtype', 'half',
'--max-model-len', '16384', # 这是你发送和检索的最大 token 输入和输出长度
'--enable-chunked-prefill', 'true',
'--tensor-parallel-size', '1'
], stdout=subprocess.PIPE, stderr=subprocess.PIPE, start_new_session=True)
好的,这就是我加载模型的方式,通过在后台启动 vllm 服务器,因为如果你在 Jupyter Notebook 中,它会卡在运行 vllm 的进程中,而我们无法公开它(我认为我们可以,但我只是这样做)。在这里我们可以看到
--trust-remote-code,所以它信任远程代码。--dtype,half以减少内存使用。--max-model-len,用于你想要发送和检索的最大 token 输入 + 输出总长度。--enable-chunked-prefill,指的是在生成开始之前将 token 预加载到模型中的过程。--tensor-parallel-size,将模型跨多个 GPU 拆分以加速推理。
通过这样做,我们不会受到 T4 的限制,因为
- 注意 CUDA 内存溢出错误(我们的 VRAM 限制为 15GB)
- Colab 的 GPU 内存约束可能需要参数调整
- 12 GB 的 RAM,足够了……我认为。
现在运行它。
Subprocess
好的,由于我们正在使用 subprocess 并且使用 start_new_session 设置为 true,我们通常无法管道输出,如果出现错误,我们无法看到它,直到它报错。
import requests
def check_vllm_status():
try:
response = requests.get("http://localhost:8000/health")
if response.status_code == 200:
print("vllm 服务器正在运行")
return True
except requests.exceptions.ConnectionError:
print("vllm 服务器未运行")
return False
try:
# 监控进程
while True:
if check_vllm_status() == True:
print("vllm 服务器已准备好服务。")
break
else:
print("vllm 服务器已停止。")
stdout, stderr = vllm_process.communicate(timeout=10)
print(f"STDOUT: {stdout.decode('utf-8')}")
print(f"STDERR: {stderr.decode('utf-8')}")
break
time.sleep(5) # 每秒检查一次
except KeyboardInterrupt:
print("停止检查 vllm...")
它将每 5 秒检查一次,并尝试管道输出,如果出现错误,或者将打印 vllm stderr 和 out。如果 vllm 一切正常,那么你可以继续进行下一个代码块。
创建调用 vLLM 的函数
import requests
import json
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from fastapi.responses import StreamingResponse
import requests
# 输入的请求模式
class QuestionRequest(BaseModel):
question: str
model: str = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B" # 默认模型
def ask_model(question: str, model: str):
"""
向模型服务器发送请求并获取响应。
"""
url = "http://localhost:8000/v1/chat/completions" # 如果 URL 不同,请调整
headers = {"Content-Type": "application/json"}
data = {
"model": model,
"messages": [{
"role": "user",
"content": question
}]
}
response = requests.post(url, headers=headers, json=data)
response.raise_for_status() # 为 HTTP 错误引发异常
return response.json()
# 用法:
result = ask_model("法国的首都是哪里?", "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B")
print(json.dumps(result, indent=2))
def stream_llm_response(question:str, model:str):
url = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": model,
"messages": [{"role": "user", "content": question}],
"stream": True # 🔥 启用流式传输
}
with requests.post(url, headers=headers, json=data, stream=True) as response:
for line in response.iter_lines():
if line:
# OpenAI 风格的流式响应以 "data: " 为前缀
decoded_line = line.decode("utf-8").replace("data: ", "")
yield decoded_line + "\\n"
我们有两个 API 用于测试,
ask_model 函数
目的: 向 vLLM 服务器发送请求并等待完整响应。
工作原理:
- 构建一个到
http://localhost:8000/v1/chat/completions的 POST 请求。 - 发送一个 JSON 有效负载,其中包含:
- 模型名称。
- 用户的问题(作为消息)。
- 等待响应并将其作为 JSON 返回。
主要特点:
- 阻塞调用(等待直到生成完整响应)。
- 如果请求失败,则引发异常。
stream_llm_response 函数
目的: 从 vLLM 流式传输响应,而不是等待完整输出。
工作原理:
- 发送一个 POST 请求,其中
"stream": True,启用分块响应。 - 使用
response.iter_lines()实时处理响应块。 - 每个接收到的块都经过解码并作为流生成。
主要特点:
- 非阻塞流式传输(对于聊天机器人和交互式应用程序很有用)。
- 数据以小部分返回,减少感知延迟。
我们对其进行了测试,因此它输出了类似这样的内容
{
"id": "chatcmpl-680bc07cd6de42e7a00a50dfbd99e833",
"object": "chat.completion",
"created": 1738129381,
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "<think>\\n好的,所以我正在尝试找出法国的首都是哪里。嗯,我记得听说过一些以神话或类似事物命名的城市。让我想想。我想 Neuch portfolio 是逗号命名的地方。是的,没错,直到有时他们改变了它,但我认为它现在仍然在那里。然后是 Charles-de-Lorraine。我以前在各种场合都见过这个名字,可能是经理或什么的。然后我认为 Saint Mal\\u25e6e 是法国的一个重要城市。等等,我对最后一个有点困惑。那是首都还是其他地方?我想首都曾经让我大吃一惊,但我仍然不记得了。让我想想脑海中浮现的名字。也许是巴黎?但还有别的吗?我还听说过像 qualification、Guiness 和 Agoura 这样的地方也是以神话人物命名的,但它们是首都吗?我不这么认为。所以在著名的城市中,也许 Neuch portfolio、Charles-de-Lorraine 和 Saint Mal\\u25e6e 是首都的预期名称,但我不确定是哪一个。等等,我想我可能搞混了一些。让我尝试查找实际的首都。法国的首都是\\u5c55\\u51fa东部地区的一个城市。哦,对了,有一个叫做 Place de la Confluense 的特殊地方。也许那里是首都。所以我认为首都 Place de la Confluense,而不是城市名称。所以首都不是城镇;它是一个相当静脉形状的区域。但我有点困惑,因为有些人可能只将城镇称为首都,但实际上,它是一个更大的区域。所以为了回答这个问题,法国的首都是 Place de la Confluense,其正式名称是 la Confluense。我不完全确定是否还有其他重要的城市或名称,但据我所知,我列出的其他城市可能是历史名城,但并非完全是首都。也许 \\u6bebot\\u00e9 家族的名字有时仍然用于首都,但我认为这不是实际名称。所以总而言之,首都是 Place de la Confluense,正确的名称是 \\"la Confluense.\\"。像 Neuch portfolio 这样的其他名称是地点,而不是首都。因此,总的来说,我的答案是首都是 la Confluense,在 Place de la Confluense 命名。\\n</think>\\n\\n法国的首都叫做 Place de la Confluense。它的官方名称是 \\"la Confluense.\\"",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 550,
"completion_tokens": 540,
"prompt_tokens_details": null
},
"prompt_logprobs": null
}
API Pathing
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
import nest_asyncio
from pyngrok import ngrok
import uvicorn
import getpass
from pyngrok import ngrok, conf
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)
@app.get('/')
async def root():
return {'hello': 'world'}
@app.post("/api/v1/generate-response")
def generate_response(request: QuestionRequest):
"""
用于从模型生成响应的 API 端点。
"""
try:
response = ask_model(request.question, request.model)
return {"response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/v1/generate-response-stream")
def stream_response(request:QuestionRequest):
try:
response = stream_llm_response(request.question, request.model)
return StreamingResponse(response, media_type="text/event-stream")
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
好的,现在我们为我们创建的每个函数创建 API 路径,每个 API 将使用不同的函数,它将使用流式方法还是仅仅生成响应但阻塞。在这里我们只需要一些快速的东西,所以我们将允许一切。如果发生错误,我们只需返回内部服务器错误并详细说明错误。
ngrok -> public test
! ngrok config add-authtoken ${your-ngrok-token}
现在我们将添加配置 token,只需从 ngork 仪表板 这里 复制粘贴你的 token。
Expose it
之后我们公开它。
port = 8081
# 打开一个 ngrok 隧道到 HTTP 服务器
public_url = ngrok.connect(port).public_url
print(f" * ngrok 隧道 \"{public_url}\" -> \"http://127.0.0.1:{port}\"")
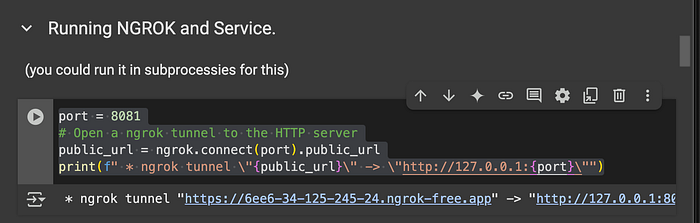
我们得到了返回的公开隧道,可以使用 curl 或 postman 访问。
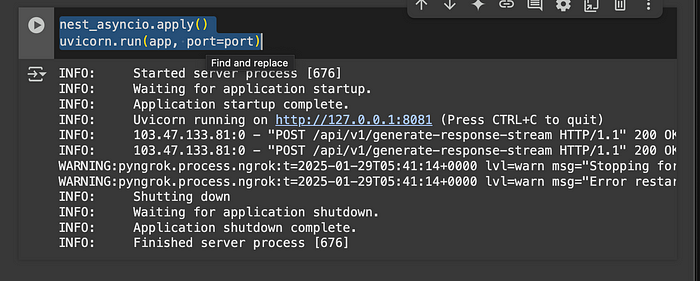
nest_asyncio.apply()
uvicorn.run(app, port=port)
最后用这个结束,以运行服务,whoalaaa 它完美运行了……我认为。
现在你可以像这样访问它。
curl --location 'https://6ee6-34-125-245-24.ngrok-free.app/api/v1/generate-response-stream' \
--header 'Content-Type: application/json' \
--data '{
"question": "巴黎在哪里?",
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
}'
并得到更像这样的响应,如果你选择了每个 token 流响应。
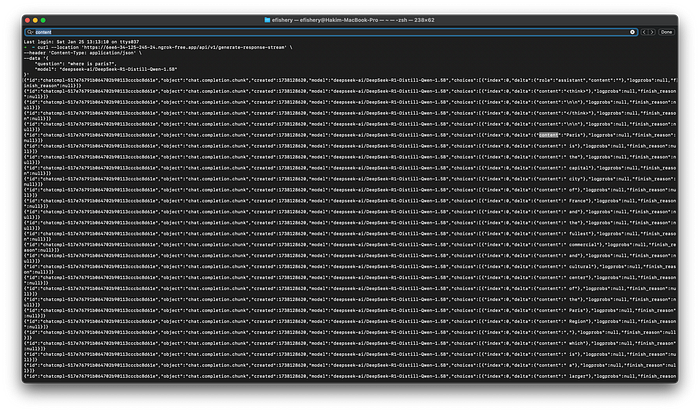
通过流式响应返回每个 token
而且它非常好,响应速度相当快……我认为,但输出答案非常好(如果你想要更简洁的答案,比如关于代码,少一些关于创造力)。但对于 Facebook 的 Llama 之后的开源模型来说,这已经很不错了。
完整代码可以在这里访问
结束。
在所有这些之后,我会向你们推荐……如果你有钱,买 GPU,如果你想在本地运行它,但你需要一个相当不错的 GPU 和电费的开销,但你可以拥有你自己的数据。使用 chat.deepseek.com,如果你想使用满血的 deepseek llm (具有 671B 参数),你可以使用这个,但你的数据不仅仅是你自己的,就像 Claude 和 OpenAi 等任何其他平台一样。