为什么你应该使用 io_uring 进行网络 io 操作
io_uring 是 Linux 内核的异步接口,可能有益于网络。对于文件 I/O(输入/输出)来说,这是一个很大的胜利,但对于已经具有非阻塞 API 的网络 I/O 来说,这可能只提供适度的收益。收益可能来自以下方面:
- 减少了服务器上执行大量上下文切换的系统调用数量
- 用于文件和网络 I/O 的统一异步 API
许多功能将很快在红帽企业 Linux 9.3 中提供, io_uring 该版本随内核版本 5.14 一起分发。最新的 io_uring 功能目前在 Fedora 37 中可用。
什么是io_uring?
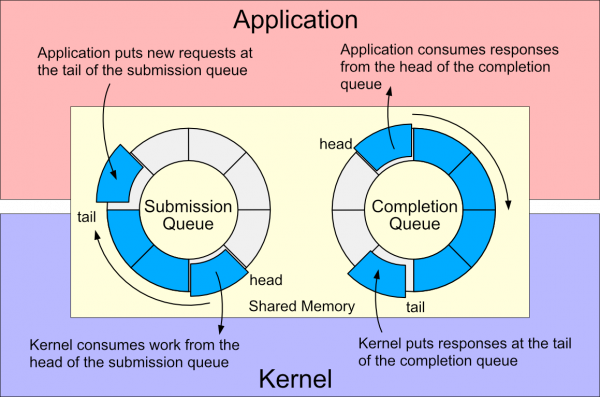
io_uring 是 Linux 内核的异步 I/O 接口。一个 io_uring 是共享内存中的一对环形缓冲区,用作用户空间和内核之间的队列:
- 提交队列 (SQ):用户空间进程使用提交队列向内核发送异步 I/O 请求。
- 完成队列 (CQ):内核使用完成队列将异步 I/O 操作的结果发送回用户空间。
图 1 中的图表显示了如何在 io_uring 用户空间和 Linux 内核之间提供异步接口。
{kind=link}
图 1:io_uring 提交和完成队列的可视化表示。
此接口使应用程序能够从传统的基于就绪性的 I/O 模型转变为新的基于完成的模型,其中异步文件和网络 I/O 共享统一的 API。
系统调用接口
Linux 内核 API 有 io_uring 3 个系统调用:
io_uring_setup:设置用于执行异步 I/O 的上下文io_uring_register:为异步 I/O 注册文件或用户缓冲区io_uring_enter:启动和/或完成异步 I/O
前两个系统调用用于设置 io_uring 实例,并选择性地预注册将由操作引用 io_uring 的缓冲区。只需 io_uring_enter 调用队列提交和使用。 io_uring_enter 呼叫的成本可以分摊到多个 I/O 操作中。对于非常繁忙的服务器,可以通过启用内核中提交队列的繁忙轮询来完全避免 io_uring_enter 调用。这是以内核线程消耗 CPU 为代价的。
syscall API
liburing 库提供了一种方便的使用 io_uring 方式,隐藏了一些复杂性,并提供函数来准备所有类型的 I/O 操作以供提交。
用户进程创建一个 io_uring :
struct io_uring ring;
io_uring_queue_init(QUEUE_DEPTH, &ring, 0);
然后将操作提交到 io_uring 提交队列:
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
io_uring_prep_readv(sqe, client_socket, iov, 1, 0);
io_uring_sqe_set_data(sqe, user_data);
io_uring_submit(&ring);
等待该过程完成:
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(&ring, &cqe);
并使用响应:
user_data = io_uring_cqe_get_data(cqe);
if (cqe->res < 0) {
// handle error
} else {
// handle response
}
io_uring_cqe_seen(&ring, cqe);
使用 io_uring 是将应用程序从 API 中解放的首选方式。Liburing 具有与最新内核开发工作相同的功能,并且与缺乏最新 io_uring 功能的旧内核 io_uring 向后兼容。
将io_uring用于网络 I/O
我们将通过使用 liburing API 编写一个简单的回显服务器来尝试 io_uring 网络 I/O。然后,我们将了解如何最大程度地减少高速率并发工作负载所需的系统调用数。
一个简单的回显服务器
出现在 Berkeley Software Distribution(BSD) Unix中的经典echo服务器看起来像这样:
client_fd = accept(listen_fd, &client_addr, &client_addrlen);
for (;;) {
numRead = read(client_fd, buf, BUF_SIZE);
if (numRead <= 0) // exit loop on EOF or error
break;
if (write(client_fd, buf, numRead) != numRead) {
// handle write error
}
}
close(client_fd);
服务器可以是多线程的,也可以使用非阻塞 I/O 来支持并发请求。无论采用何种形式,服务器都需要每个客户端会话至少 5 个系统调用,用于接受、读取、写入、读取以检测 EOF,然后关闭。
一个简单的 io_uring 改写会导致异步服务器一次提交一个操作,并在提交下一个操作之前等待完成。基于简单 io_uring 服务器的伪代码省略了样板和错误处理,如下所示:
add_accept_request(listen_socket, &client_addr, &client_addr_len);
io_uring_submit(&ring);
while (1) {
int ret = io_uring_wait_cqe(&ring, &cqe);
struct request *req = (struct request *) cqe->user_data;
switch (req->type) {
case ACCEPT:
add_accept_request(listen_socket,
&client_addr, &client_addr_len);
add_read_request(cqe->res);
io_uring_submit(&ring);
break;
case READ:
if (cqe->res <= 0) {
add_close_request(req);
} else {
add_write_request(req);
}
io_uring_submit(&ring);
break;
case WRITE:
add_read_request(req->socket);
io_uring_submit(&ring);
break;
case CLOSE:
free_request(req);
break;
default:
fprintf(stderr, "Unexpected req type %d\n", req->type);
break;
}
io_uring_cqe_seen(&ring, cqe);
}
在此 io_uring 示例中,服务器仍需要至少 4 个系统调用来处理每个新客户端。此处实现的唯一节省是同时提交读取和新的接受请求。这可以在以下接收 1,000 个客户端请求的回显服务器的 strace 输出中看到。
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
99.99 0.445109 111 4001 io_uring_enter
0.01 0.000063 63 1 brk
------ ----------- ----------- --------- --------- ----------------
100.00 0.445172 111 4002 total
合并提交
在 echo 服务器中,链接 I/O 操作的机会有限,因为我们需要先完成读取,然后才能知道可以写入多少字节。我们可以通过使用新的 io_uring 固定文件功能来链接接受和读取,但我们已经能够同时提交读取请求和新的接受请求,因此可能没有太多收获。
我们可以同时提交独立的操作,因此我们可以将写入的提交和后续的读取结合起来。这会将每个客户端请求的系统调用计数减少到 3 个:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
99.93 0.438697 146 3001 io_uring_enter
0.07 0.000325 325 1 brk
------ ----------- ----------- --------- --------- ----------------
100.00 0.439022 146 3002 total
排空完成队列
如果我们在调用 io_uring_submit 之前处理所有排队的完成,则可以将更多的工作合并到同一个提交中。为此,我们可以结合使用 io_uring_wait_cqe 等待工作,然后调用 io_uring_peek_cqe 来检查完成队列是否有更多可以处理的条目。这样可以避免在完成队列为空时在繁忙循环中旋转,同时尽可能快地耗尽完成队列。
主循环的伪代码现在如下所示:
while (1) {
int submissions = 0;
int ret = io_uring_wait_cqe(&ring, &cqe);
while (1) {
struct request *req = (struct request *) cqe->user_data;
switch (req->type) {
case ACCEPT:
add_accept_request(listen_socket,
&client_addr, &client_addr_len);
add_read_request(cqe->res);
submissions += 2;
break;
case READ:
if (cqe->res <= 0) {
add_close_request(req);
submissions += 1;
} else {
add_write_request(req);
add_read_request(req->socket);
submissions += 2;
}
break;
case WRITE:
break;
case CLOSE:
free_request(req);
break;
default:
fprintf(stderr, "Unexpected req type %d\n", req->type);
break;
}
io_uring_cqe_seen(&ring, cqe);
if (io_uring_sq_space_left(&ring) < MAX_SQE_PER_LOOP) {
break; // the submission queue is full
}
ret = io_uring_peek_cqe(&ring, &cqe);
if (ret == -EAGAIN) {
break; // no remaining work in completion queue
}
}
if (submissions > 0) {
io_uring_submit(&ring);
}
}
对于 1,000 个客户端请求,所有可用工作的批处理提交结果比之前的结果有了显著改进,如以下 strace 输出所示:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
99.91 0.324226 4104 79 io_uring_enter
0.09 0.000286 286 1 brk
------ ----------- ----------- --------- --------- ----------------
100.00 0.324512 4056 80 total
这里的改进是巨大的,每个系统调用处理的客户端请求超过 12 个,或者每个系统调用平均处理超过 60 个 I/O 操作。此比率随着服务器繁忙而提高,这可以通过在服务器中启用日志记录来证明:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
68.86 0.225228 42 5308 286 write
31.13 0.101831 4427 23 io_uring_enter
0.00 0.000009 9 1 brk
------ ----------- ----------- --------- --------- ----------------
100.00 0.327068 61 5332 286 total
这表明,当服务器有更多的工作要做时,更多的操作有时间完成,因此可以在单个系统调用中提交更多的 io_uring 新工作。echo 服务器响应 1,000 个客户端回显请求,或者仅用 23 个系统调用即可完成 5,000 个套接字 I/O 操作。
值得注意的是,随着提交的工作量增加, io_uring_enter 在系统调用中花费的时间也会增加。在某个时刻,可能需要限制提交批处理的大小或在内核中启用提交队列轮询。
网络 I/O 的优势
io_uring 网络 I/O 的主要优点是现代异步 API,它易于使用,并为文件和网络 I/O 提供统一的语义。
网络 I/O io_uring 的潜在性能优势是减少系统调用的数量。这可以为大量小型操作提供最大的好处,在这些操作中,可以显著减少系统调用开销和上下文切换的数量。
还可以通过在发送 io_uring 请求之前向内核预先注册资源来避免在繁忙的服务器上进行累积昂贵的操作。可以注册文件槽和缓冲区,以避免每个 I/O 操作的查找和引用成本。
注册的文件槽(称为固定文件)还可以将接受与读取或写入链接在一起,而无需往返用户空间。提交队列条目 (SQE) 将指定一个固定的文件槽来存储接受的返回值,然后链接的 SQE 将在 I/O 操作中引用该值。
局限性
理论上,可以使用标志 IOSQE_IO_LINK 将操作链接在一起。但是,对于读取和写入,没有机制将读取操作的返回值强制转换为后续写入操作的参数集。这将链接操作的范围限制为语义排序,例如“写入然后读取”或“写入然后关闭”,以及接受后跟读取或写入。
另一个考虑因素是, io_uring 这是一个相对较新的 Linux 内核功能,仍在积极开发中。性能还有改进的空间,某些 io_uring 功能可能仍会从优化工作中受益。
io_uring 目前是一个特定于Linux的API,因此将其集成到libuv等跨平台库中可能会带来一些挑战。
最新功能
最新推出的功能 io_uring 是多拍接受(从 5.19 开始提供)和多拍接收(从 6.0 开始)。多重接受允许应用程序发出单个接受 SQE,每当内核收到新的连接请求时,该 SQE 将重复发布 CQE。每当新接收的数据可用时,多次接收同样会发布 CQE。这些功能在 Fedora 37 中可用,但在 RHEL 9 中尚不可用。
结论
API io_uring 是一个功能齐全的异步 I/O 接口,可为文件和网络 I/O 提供统一的语义。它有可能单独为网络 I/O 提供适度的性能优势,并为混合文件和网络 I/O 应用程序工作负载提供更大的优势。
流行的异步 I/O 库(如 libuv)是多平台的,这使得采用特定于 Linux 的 API 更具挑战性。添加到 io_uring 库时,应同时添加文件 I/O 和网络 I/O,以便充分利用io_uring的异步完成模型。
与网络I/O相关的功能开发和优化工作 io_uring 将主要由网络应用程序的进一步采用所推动。现在是时候集成到 io_uring 您的应用程序和 I/O 库中了。
更多信息
浏览以下资源以了解更多信息: